
This article deals with the reliable and efficient storage of ‘Big Data’, by which is meant the vast quantities of data that are stored in data centers worldwide. Given that storage units are prone to failure, to protect against data loss, data pertaining to a data file is stored in distributed and redundant fashion across multiple storage units. While replication was and continues to be commonly employed, the explosive growth in amount of data that is generated on a daily basis, has forced the industry to increasingly turn to erasure codes such as the Reed-Solomon code. The reason for this is that erasure codes have the potential to keep to a minimum, the storage overhead required to ensure a given level of reliability. There is also need for storing data such that the system can recover efficiently from the failure of a single storage unit. Conventional erasure-coding techniques are inefficient in this respect. To address this situation, coding theorists have come up with two new classes of erasure codes known respectively as regenerating codes and locally recoverable codes. These codes have served both to address the needs of industry as well as enrich coding theory by adding two new branches to the discipline. This article provides an overview of these exciting new developments, from the (somewhat biased) perspective of the authors.
The setting of the work on developing erasure codes for the storage of Big Data is that of a large data center. The total amount of data stored in 2018 across data centers worldwide, is estimated to be in excess of 14001400 exabytes [1]. These centers are very expensive to build and operate. For example, the NSA data center in the US is estimated to have cost several billion dollars to build, consume about 65MW of power each year and use over a million gallons of water per day [2]. Thus while arguably, the most important consideration in data storage is that of protection against data loss, given the explosive growth in the amount of data generated and the costs involved in storing such data, minimizing storage overhead is an important second consideration. Yet another consideration, that has recently risen in importance, is that of efficiently handling the commonplace occurrence of the failure of an individual storage unit. The focus of this article is on identifying efficient means of storing data while keeping all three considerations in mind. We note as a disclaimer, that the article is not intended to be an unbiased survey of the discipline, as the article emphasizes those aspects of the discipline to which the authors have had greater contribution. A more detailed and balanced coverage of the topic can be found in the recent survey article, also by the authors [3].
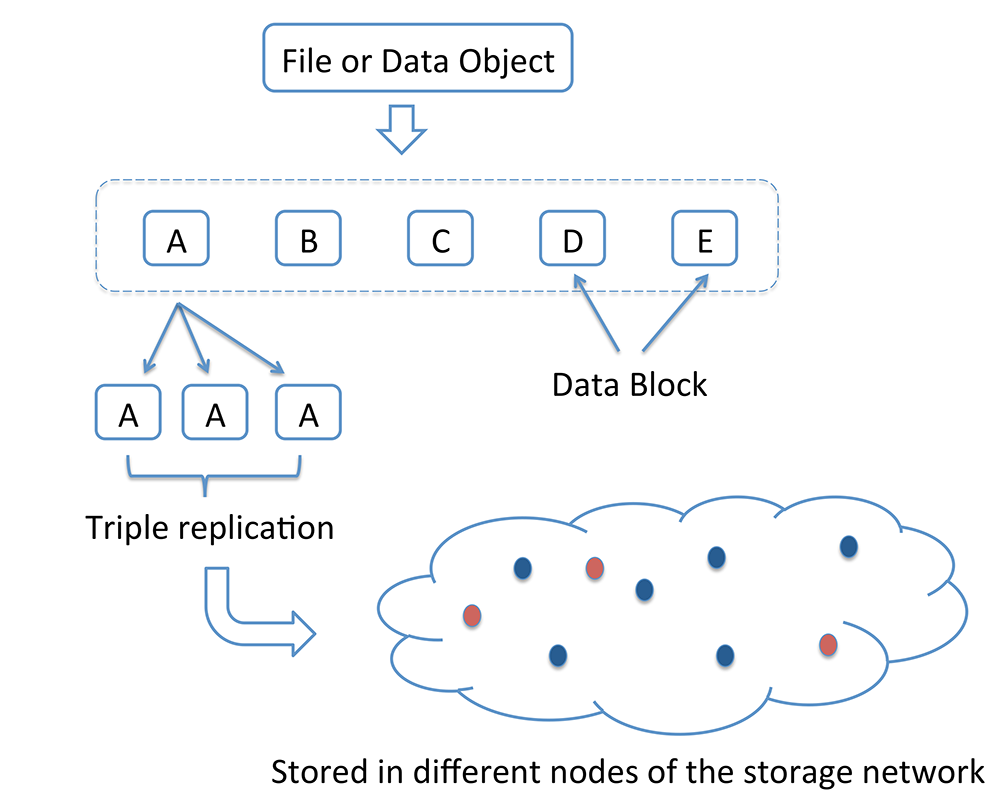
The key strategy adopted to protect against data loss, given that individual storage units are prone to failure, is to store data pertaining to a single file in distributed and redundant fashion across multiple storage units [3]. The simplest means of introducing redundancy is replication of the data file, with triple replication being in common use [4], see Figure 1.
A more efficient option is to use an ![]() erasure code. Figure 2 shows the procedure for encoding data using an
erasure code. Figure 2 shows the procedure for encoding data using an
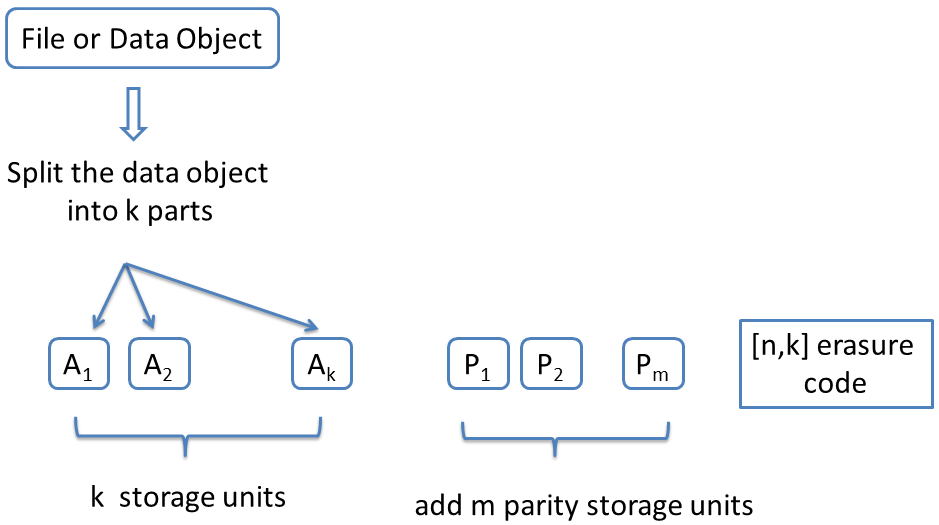
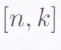 erasure code.
erasure code.erasure code. In an ![]() erasure code, the data file is first split into
erasure code, the data file is first split into 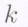 fragments. To this, an additional m=(n−k)m=(n−k) redundant fragments are added making for a total of
fragments. To this, an additional m=(n−k)m=(n−k) redundant fragments are added making for a total of ![]() fragments. Each fragment is stored on a different storage unit. Within the class of erasure codes, maximum distance separable codes (MDS) are the most efficient in terms of offering reliability for a given amount of storage overhead. An
fragments. Each fragment is stored on a different storage unit. Within the class of erasure codes, maximum distance separable codes (MDS) are the most efficient in terms of offering reliability for a given amount of storage overhead. An ![]() MDS code has the following defining property. The entire data file can be recovered if one has access to any collection of fragments. We will refer to this as the ‘any of
MDS code has the following defining property. The entire data file can be recovered if one has access to any collection of fragments. We will refer to this as the ‘any of ![]() property. Thus, an
property. Thus, an ![]() MDS code can recover from the failure of any
MDS code can recover from the failure of any ![]() fragments. To protect against the failure of any
fragments. To protect against the failure of any 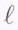 nodes, a replication code must create
nodes, a replication code must create ![]() replicas, resulting in a storage overhead of
replicas, resulting in a storage overhead of ![]() In contrast, the storage overhead of an MDS code that is resilient against
In contrast, the storage overhead of an MDS code that is resilient against 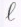 failures has overhead
failures has overhead ![]() For example, with
For example, with ![]() the storage overheads of the two schemes, replication and erasure coding, are respectively given by 3 and 1.5.
the storage overheads of the two schemes, replication and erasure coding, are respectively given by 3 and 1.5.
The best known of all MDS codes is the Reed-Solomon (RS) code [5]. The symbol alphabet of an RS code is a finite field ![]() A finite field
A finite field ![]() is a collection of
is a collection of 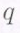 elements together with two operations, addition and multiplication that obey the rules we are accustomed to such as
elements together with two operations, addition and multiplication that obey the rules we are accustomed to such as ![]()
![]() etc. As an example, a finite field
etc. As an example, a finite field ![]() of size
of size ![]() is composed of the elements
is composed of the elements ![]() along with two operations: addition (mod3)(mod3) and multiplication (mod3)(mod3). The corresponding addition and multiplication tables are presented in Figure 3.
along with two operations: addition (mod3)(mod3) and multiplication (mod3)(mod3). The corresponding addition and multiplication tables are presented in Figure 3.
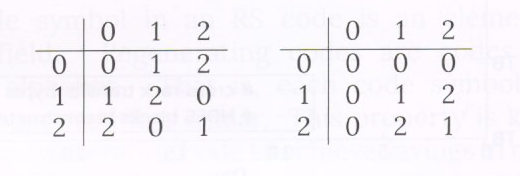
Similar addition and multiplication tables can be generated for finite fields of size ![]() where
where ![]() is a prime number such as
is a prime number such as ![]() In general, finite fields of size
In general, finite fields of size ![]() exist whenever
exist whenever ![]() can be expressed as power of a prime number
can be expressed as power of a prime number ![]() for some positive integer ee. However, the arithmetic there is more involved. For our purposes, it suffices to imagine that we are working in some suitably large finite field. The explanation from here on is agnostic to the inner workings of operations in the finite field.
for some positive integer ee. However, the arithmetic there is more involved. For our purposes, it suffices to imagine that we are working in some suitably large finite field. The explanation from here on is agnostic to the inner workings of operations in the finite field.
We explain in brief, the construction of an ![]() RS code. Let the symbols
RS code. Let the symbols ![]() each taking on values in a finite field
each taking on values in a finite field ![]() represent the
represent the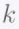 message symbols. Let
message symbols. Let ![]() be an arbitrary collection of
be an arbitrary collection of 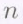 distinct elements from
distinct elements from ![]() Let the polynomial
Let the polynomial ![]() be defined by:
be defined by:
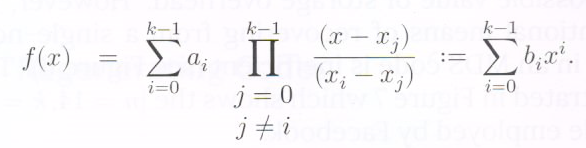
Then clearly,![]() is a polynomial of degree
is a polynomial of degree![]() such that
such that

The 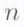 code symbols in the RS codeword corresponding to message vector
code symbols in the RS codeword corresponding to message vector 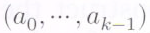 are precisely the
are precisely the 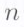 values
values ![]() The
The 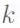 message symbols are the values
message symbols are the values 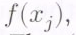 of
of 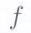 when
when 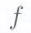 is evaluated at
is evaluated at 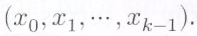 The
The  redundant symbols of an RS code are the values
redundant symbols of an RS code are the values 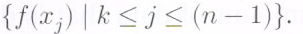
The RS code derives its ‘any  of
of  property from the fact that the polynomial
property from the fact that the polynomial  (and hence the message symbols
(and hence the message symbols ![]() can be determined from knowledge of any
can be determined from knowledge of any 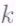 evaluations, simply by solving a nonsingular set of
evaluations, simply by solving a nonsingular set of 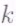 equations in the
equations in the 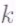 unknown coefficients
unknown coefficients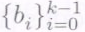 as shown below
as shown below

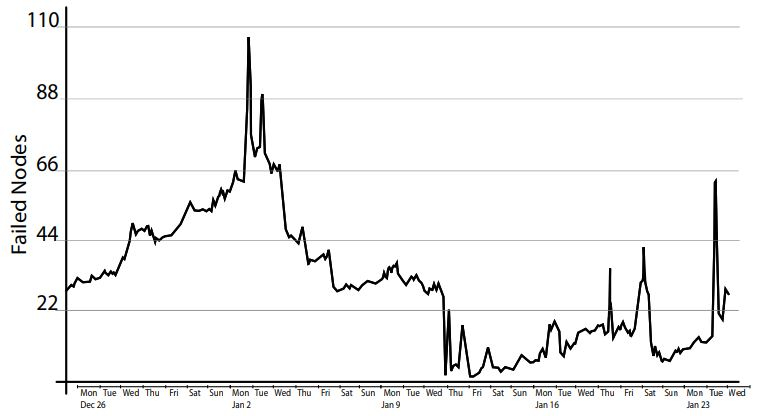
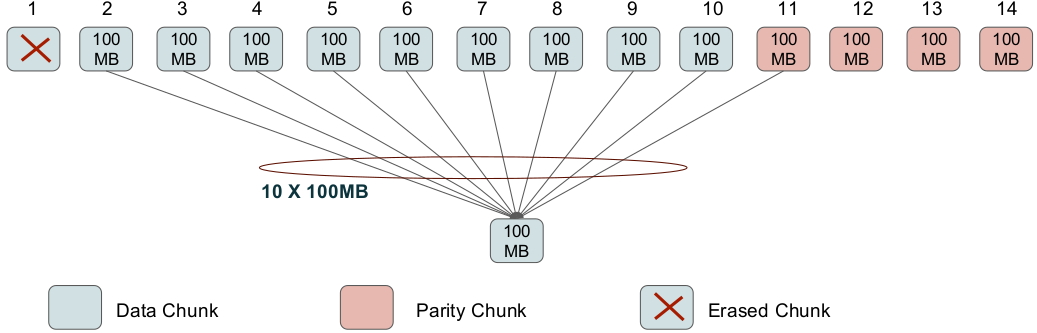
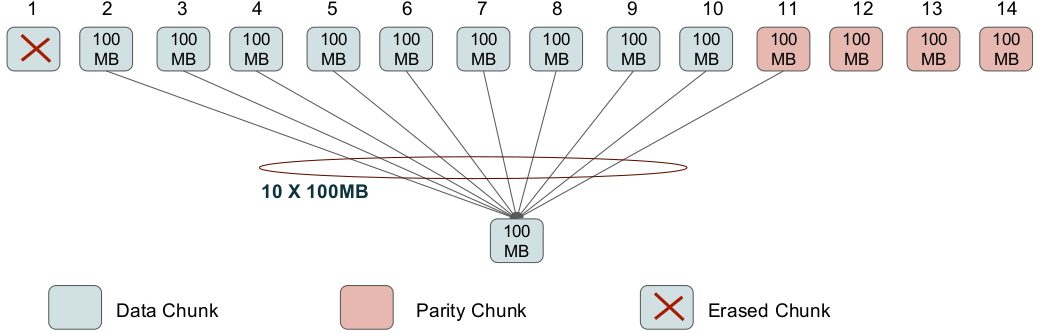
A fairly frequent occurrence in a data center is the failure of a single node (i.e., of a single storage unit). Figure 5 shows the number of single-node failures in a Facebook data center containing 30003000 nodes in all. RS codes are efficient in terms of providing the least possible value of storage overhead. However, the conventional means of recovering from a single-node failure in an MDS code is inefficient (see Figure 6). This is illustrated in Figure 7 which shows the [n=14,k=10][n=14,k=10] RS code employed by Facebook.
In Figure 7, in order to repair the code symbol in failed node 11 (similarly, for any other node), the replacement node for node 11 will contact 1010 other storage units, use their contents in conjunction with the ‘any 1010 out of 1414’ property to reconstruct the RS codeword, and thereby the lost contents of node 11. This is inefficient in 22 respects: firstly in terms of the number of nodes contacted (which is 1010 here) and secondly in terms of the total amount of data that is downloaded to restore the contents of a single, failed node. Figure 7 shows that if each failed node stores 100100MB of data, then the total download needed to recover the node is 11TB, which clearly, is inefficient.
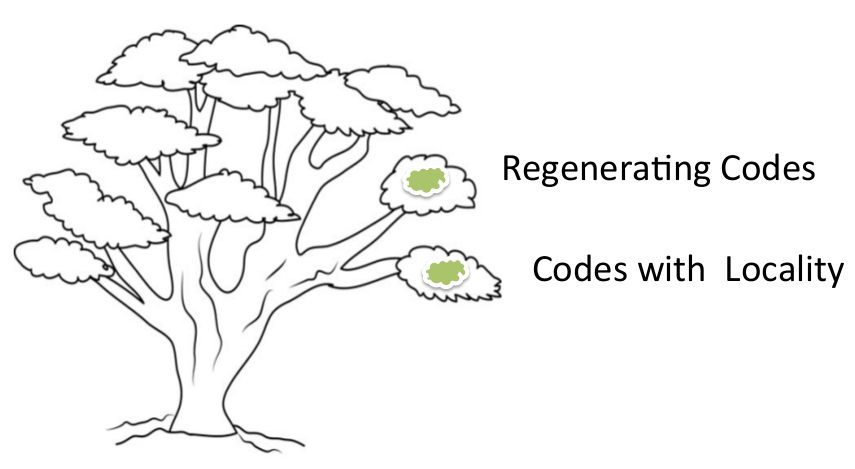
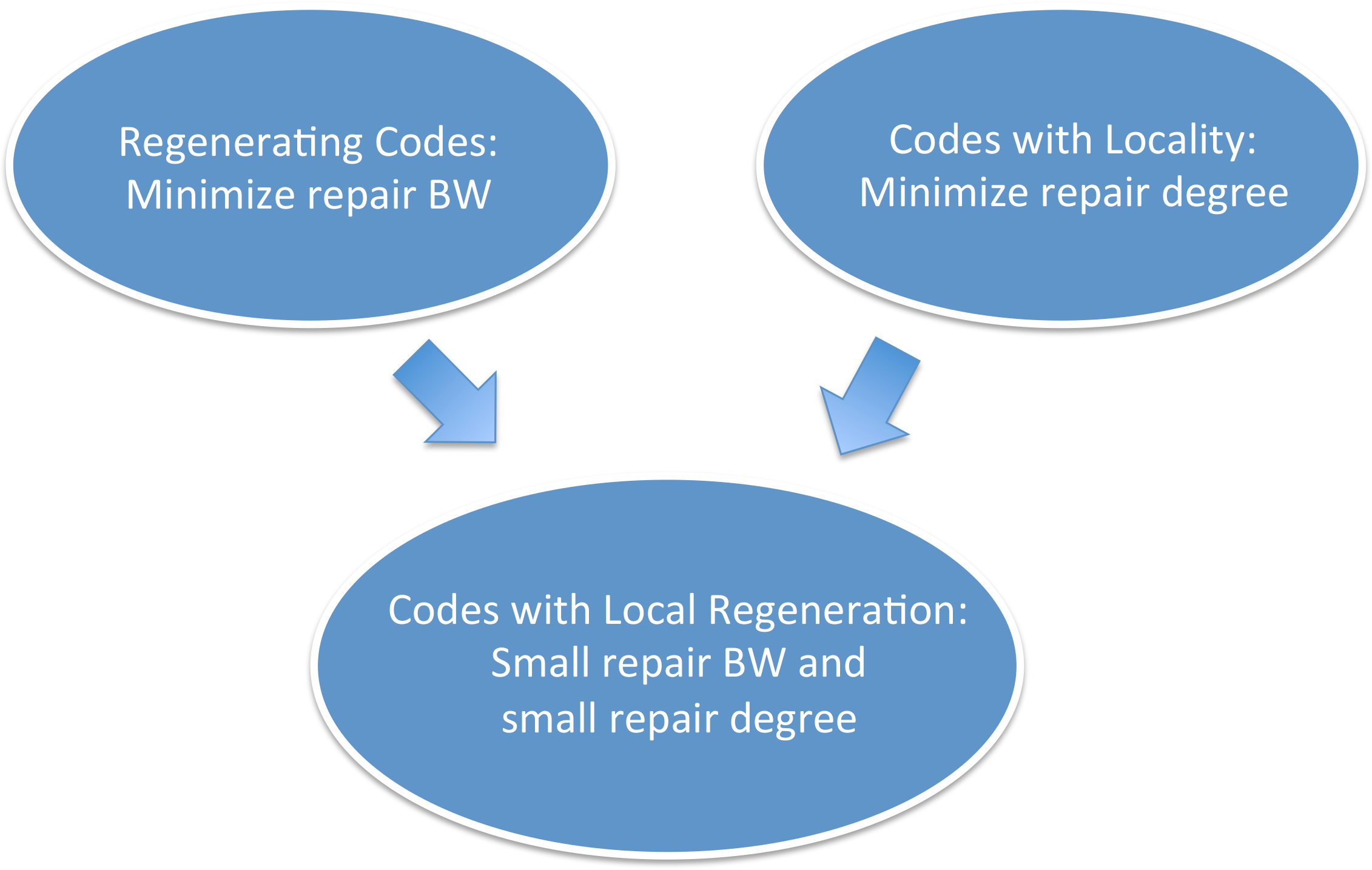
To address this issue, coding theorists came up with two new classes of codes, known respectively as regenerating codes (RGC) [9] and locally recoverable codes (LRC) [10]. LRC also go by the name codes with locality and we will interchangeably use the two terms. These developments have led to the evolution of coding theory in two new directions (see Figure 8). While these developments also resulted in finding improved methods of repairing RS codes, we will not cover them in this survey and point the reader instead, to a representative set of references on this topic [11, 12, 13]. We will also not cover variants of regenerating codes such as the piggybacking framework introduced in [14], the ϵ−ϵ−MSR framework [15], codes with cooperative repair [16] and fractional-repetition codes [17].
The goal in the case of an RGC is to reduce the amount of data that has to be downloaded to repair a failed node, termed as the repair bandwidth. The aim in the case of an LRC is to minimize the number of helper nodes contacted for repair of a failed node. This is termed as the repair degree.
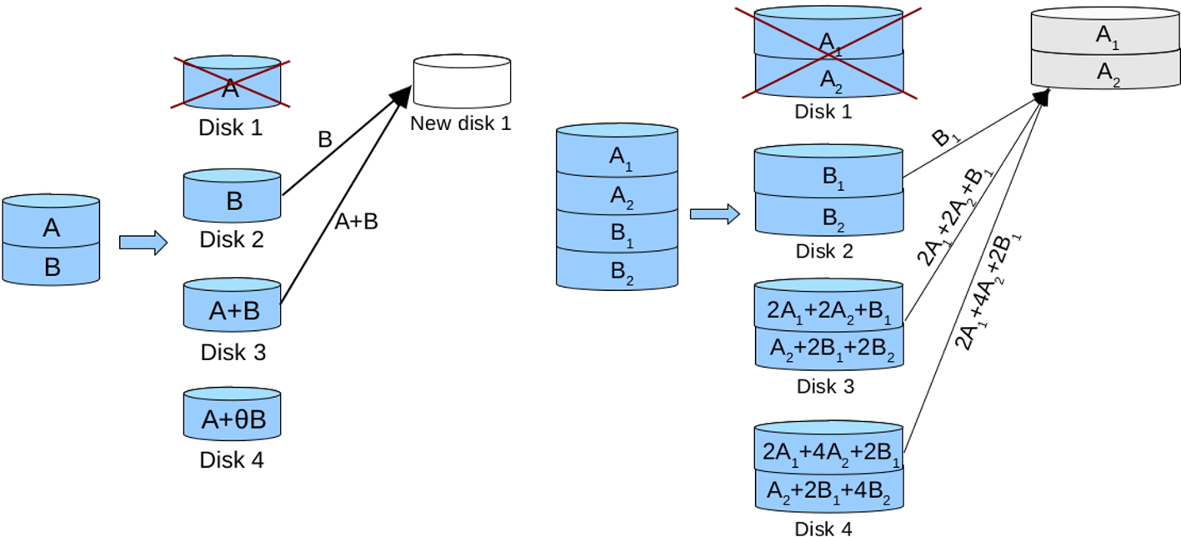
Each code symbol in an RS code is an element in a finite field. Regenerating codes are codes over a vector alphabet. That is, each code symbol is a vector as opposed to a scalar. This property is key to enabling a regenerating code to achieve savings in repair bandwidth. This is illustrated in the example depicted in Figure 9.
In Figure 9, the setup on the left represents an [4,2][4,2] MDS code. The symbols stored in the 44 nodes are respectively, A,B,A+B,A+2BA,B,A+B,A+2B. This makes the code an MDS code. However, to repair a failed node, say the node 11, that stored AA, we still have to download 22 symbols to repair the node. Consider next, the setup on the right. Here the sub-packetization level is 22, each symbol is replaced by 22 ‘half-symbols’. Thus AA is replaced by A1,A2A1,A2, BB by B1,B2B1,B2. Note that if the data stored in the remaining two parity nodes is as shown in the figure, then node 11 can be repaired by downloading 33 half-symbols in place of two full symbols, thereby achieving a reduction in repair bandwidth. Note however, that in the case of the regenerating code, we have contacted all the remaining nodes, 33 in this case, as opposed to k=2k=2 in the case of the MDS code on the left. Thus while regenerating codes reduce the repair bandwidth, they do in general, result in increased repair degree.
A regenerating code is characterized by the parameter set
{(n,k,d),(α,β),B,Fq }.{(n,k,d),(α,β),B,Fq }.
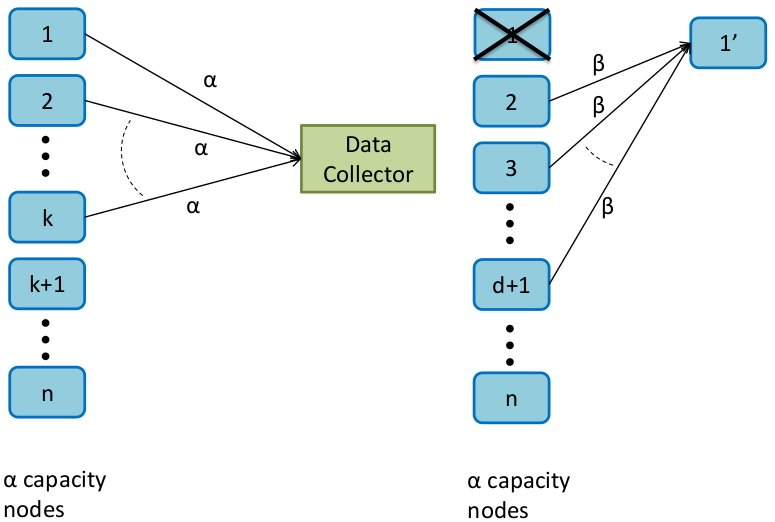
The parameter nn denotes the block length of the code, which is the number of nodes that the data associated with a codeword in the RGC is stored across. Each node stores αα symbols over FqFq. A value of α=1α=1 would indicate a scalar code, such as an RS code. Thus αα is the level of sub-packetization of the code. The parameter kk indicates that the RGC has the ‘any kk of nn’ property. This is illustrated in Figure 10, on the left. Node repair is accomplished by having the replacement of a failed node contact any dd of the remaining nodes, with k≤d≤(n−1)k≤d≤(n−1) and download ββ symbols from each of the dd helper nodes (see Figure 10, on the right). The parameter ββ is typically much smaller than αα. BB is the size of the file being stored, as measured in the number of FqFq symbols. The savings in repair bandwidth comes about since dβ<kαdβ<kα.
A cut-set bound derived from network information-flow considerations [18] gives us the following relationship [9] between code parameters:
B≤k−1∑i=0min{α,(d−i)β}.B≤∑i=0k−1min{α,(d−i)β}.
Clearly, an RGC that achieves the above bound on file size with equality is an optimal RGC. Turns out that there are many flavours of optimality, in the sense that for a given file size BB, there can be several values of the parameter pair (α,β)(α,β) for which the bound holds with equality. Two special cases of the above bounds are shown below:
B≤kα,B≤k−1∑i=0(d−i)β = kdβ–(k2)β.(1)(2)(1)B≤kα,(2)B≤∑i=0k−1(d−i)β = kdβ–(k2)β.
Codes which achieve the first upper bound are termed as Minimum Storage Regenerating (MSR) codes while those that achieve the second bound with equality are known as Minimum Bandwidth Regenerating (MBR) codes. MSR codes have the advantage of having the least possible storage overhead as they can be shown to belong to the class of MDS codes. MBR codes have the minimum possible repair bandwidth, but are not MDS. The minimum storage overhead of an MBR code is close to the value 22.
We now present a simple, yet elegant, construction of an MBR code [19]. The parameters of the construction to be described are:
{(n=5,k=3,d=4),(α=4,β=1),B=9,Fq=F2}.{(n=5,k=3,d=4),(α=4,β=1),B=9,Fq=F2}.
The file to be stored consists of a string of 99 binary digits {a1,a2,â¯,a9}{a1,a2,â¯,a9}. Thus ai∈{0,1}ai∈{0,1}. We will use the integer ii to represent the iith message symbol aiai.
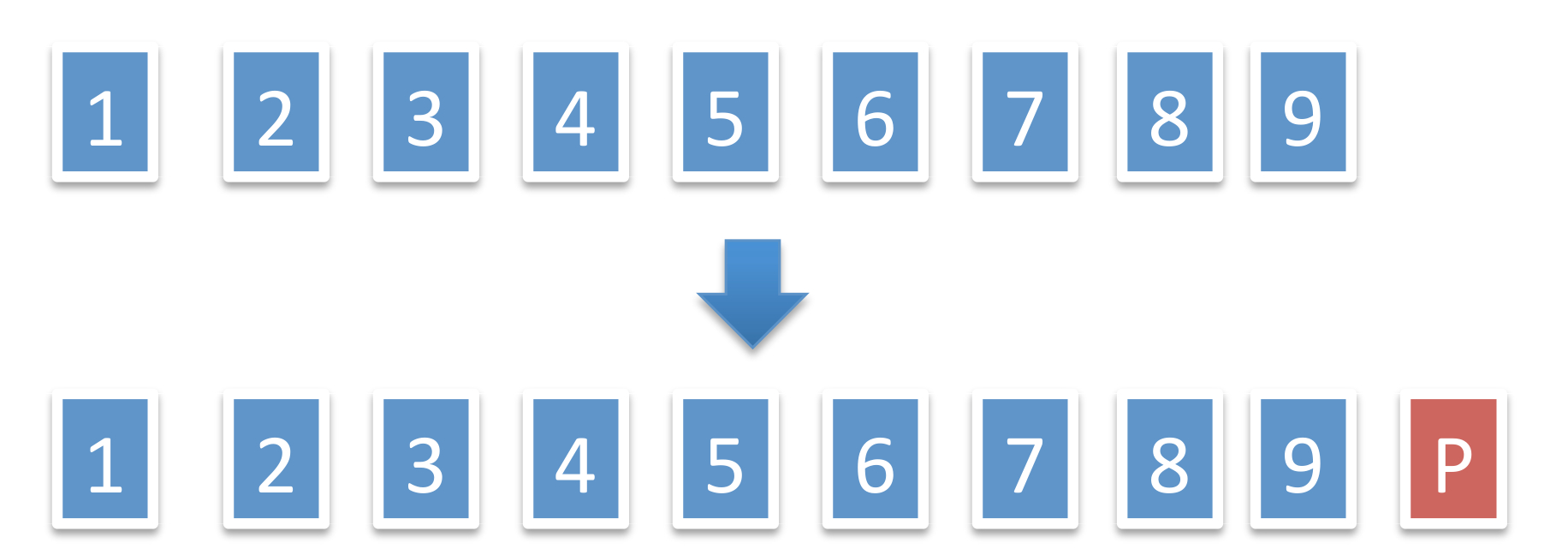
Encoding To encode the data, in the first step we add a single parity symbol PP as shown in Figure 11, i.e.,
aP=a1+a2+â¯+a9(mod2).aP=a1+a2+â¯+a9(mod2).
Note that the collection
{aiâ£1≤i≤9}∪{aP},{aiâ£1≤i≤9}∪{aP},
has the ‘any 99 of 1010 property’, i.e., a missing 1010th symbol can be recovered from the remaining 99 simply by computing their modulo 22 sum.
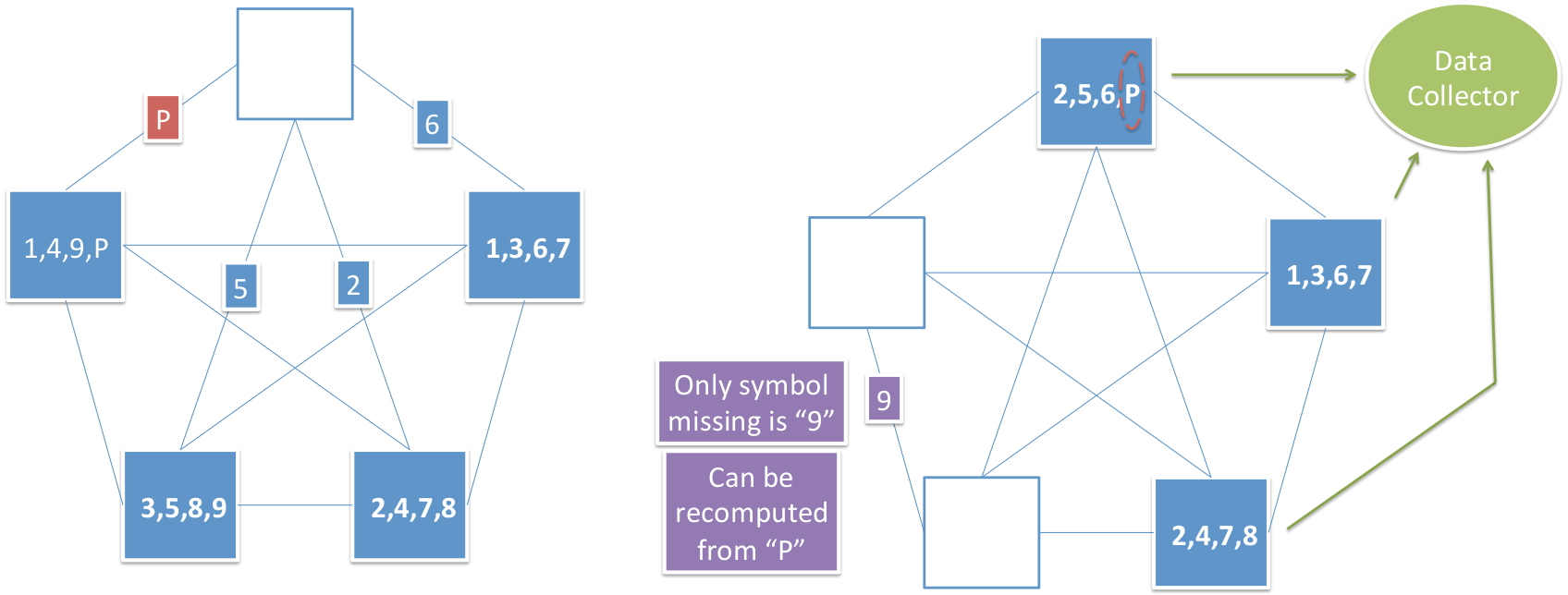
Next, we set up a graph with 55 nodes so as to form a pentagon and draw all possible edges connecting 22 nodes of the graph, i.e., form a fully-connected pentagon. The pentagon has (52)=10(52)=10 edges. We place each of the symbols aiai on a distinct edge, see Figure 12.
In the final encoding step, each node in the graph is made to store all the symbols appearing on an edge connected to that node as shown in Figure 12. Thus each node stores 44 symbols and thus in this contruction, α=4α=4. Note that every pair of nodes in the pentagon share in common, precisely one of the symbols {aiâ£1≤i≤9}∪{aP}{aiâ£1≤i≤9}∪{aP}.
Node Repair Let us assume that the node at the top of the pentagon and storing {a2,a5,a6,aP}{a2,a5,a6,aP} fails. Then repair is accomplished by the replacement node requesting each of the remaining 44 nodes to pass on to the replacement node, the symbol it shares in common with that node, see Figure 13 (left). Since each helper node passes on one symbol to aid on the repair of the failed node, it follows that β=1β=1.
Data Collection Property The data collection property of an RGC requires that the entire data file comprised in this example of 99 binary symbols, be recoverable by connecting to any k=3k=3 nodes. Suppose for example that the nodes storing {a1,a4,a9,aP}{a1,a4,a9,aP} and {a3,a5,a8,a9}{a3,a5,a8,a9} have failed. Then the data collector is required to recover the entire data file by connecting to the remaining 33 nodes as
shown in Figure 13 (right). The remaining 33 nodes store a total of 4×3=124×3=12 binary symbols. However, as every pair of nodes shares a symbol in common, only 99 of these are distinct. Now, as noted earlier, the entire data file can be recovered from any 99 symbols drawn from the set {aiâ£1≤i≤9}∪{aP}{aiâ£1≤i≤9}∪{aP} and thus we are done.
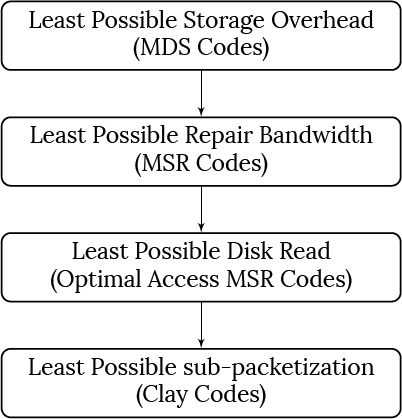
In practice there is greatest interest in using a code that has the smallest possible storage overhead. This leads directly to the subclass of MSR codes. MSR codes minimize the repair bandwidth within the class of MDS codes, i.e., within the class of codes having minimum storage overhead. Two other metrics by which a regenerating code is judged from a practical perspective are:
1. Optimal-Access In general in an RGC, while each helper node sends ββ symbols to the replacement node, these symbols may however, be derived by taking linear transformations of a larger number of symbols stored in the helper node. Potentially this could be as large as αα, the total number of symbols stored in the helper node. An RGC is said to be optimal-access (OA) if the number of symbols accessed at a helper node is equal to the number ββ, of symbols transferred to the replacement node. OA-RGC also go by the name help-by-transfer RGC.
2. Small Sub-Packetization Level: By this we mean, the least possible value αα of sub-packetization. A lower value of αα helps reduce or eliminate the phenomenon of fragmented reads. Fragmented reads take place when a storage device has its memory structured in such a way that each time a read takes place, a minimum number of JJ contiguous symbols are read off the memory. In an RGC, the ββ (or more) symbols accessed from each helper node may not be contiguous, thereby causing the number of symbols accessed to be larger than the number theoretically needed. A small value of sub-packetization helps as one can obtain contiguous reads by operating on several (in the worst case, JJ) codewords at the same time. A large value of αα would place a lower bound ≥J(kα)≥J(kα) on the amount of data needed to be stored to avoid fragmented reads.
A lower bound on the smallest possible value of the sub-packetization level αα of an OA-MSR code with d=(n−1)d=(n−1) is given by [20]:
α≥r⌈n−1r⌉.(3)(3)α≥r⌈n−1r⌉.
An OA-MSR code that achieves the bound in (3)(3) is said to have optimal sub-packetization level. MSR codes with d=(n−1)d=(n−1) while having large repair degree, have the advantage of having the smallest possible repair bandwidth of any MSR code.
There are multiple MSR constructions in the literature. In [21], the authors introduced explicit MSR constructions called Product Matrix codes that have storage overhead >(2−1k)>(2−1k). Multiple constructions that followed this construction are detailed in the survey [3]. However, these constructions lacked one or the other of the desired properties. The Clay (short for coupled-layer) code is an MSR code that is optimal in 44 respects: it is an MSR code (and hence has both minimum storage overhead and minimum repair bandwidth), it is also OA and has smallest possible level of αα (see Figure 14). In a way, the Clay code may be regarded as the culmination of work by many authors towards the construction of an RGC that meets virtually all the requirements of the industry, to the extent that it is possible for an RGC to do so.
The Clay code was independently discovered by 22 research groups, see [22],[23]. A fundamental transformation used in the construction of the Clay code was first described in [24].
We explain the structure of the Clay code using an example code having parameters:
{(n=4,k=2,d=3),(α=4,β=2),B=8,Fq=F4 (q=4)}.{(n=4,k=2,d=3),(α=4,β=2),B=8,Fq=F4 (q=4)}.
We will depict the Clay code as a data cube as shown in Figure 15 on the left. The datacube is composed of 1616 small cylinders, each associated with a symbol in FqFq. A vertical column of 44 cylinders corresponds to the 44 symbols contained in a single node (as α=4α=4). This code is required to have the following properties:
1. File Size One should be able to store B=8B=8 symbols from FqFq in redundant fashion within this datacube,
2. Data-collection property The entire data file of 88 symbols is to be recovered by connecting to any 22 nodes,
3. Node-repair property The repair of a failed node should be accomplished by downloading just 22 symbols from each of the d=3d=3 remaining nodes.
In the following, we will describe how encoding and node repair take place in a Clay code. We refer the reader to [23] for an explanation as to how data collection is accomplished in the Clay code.
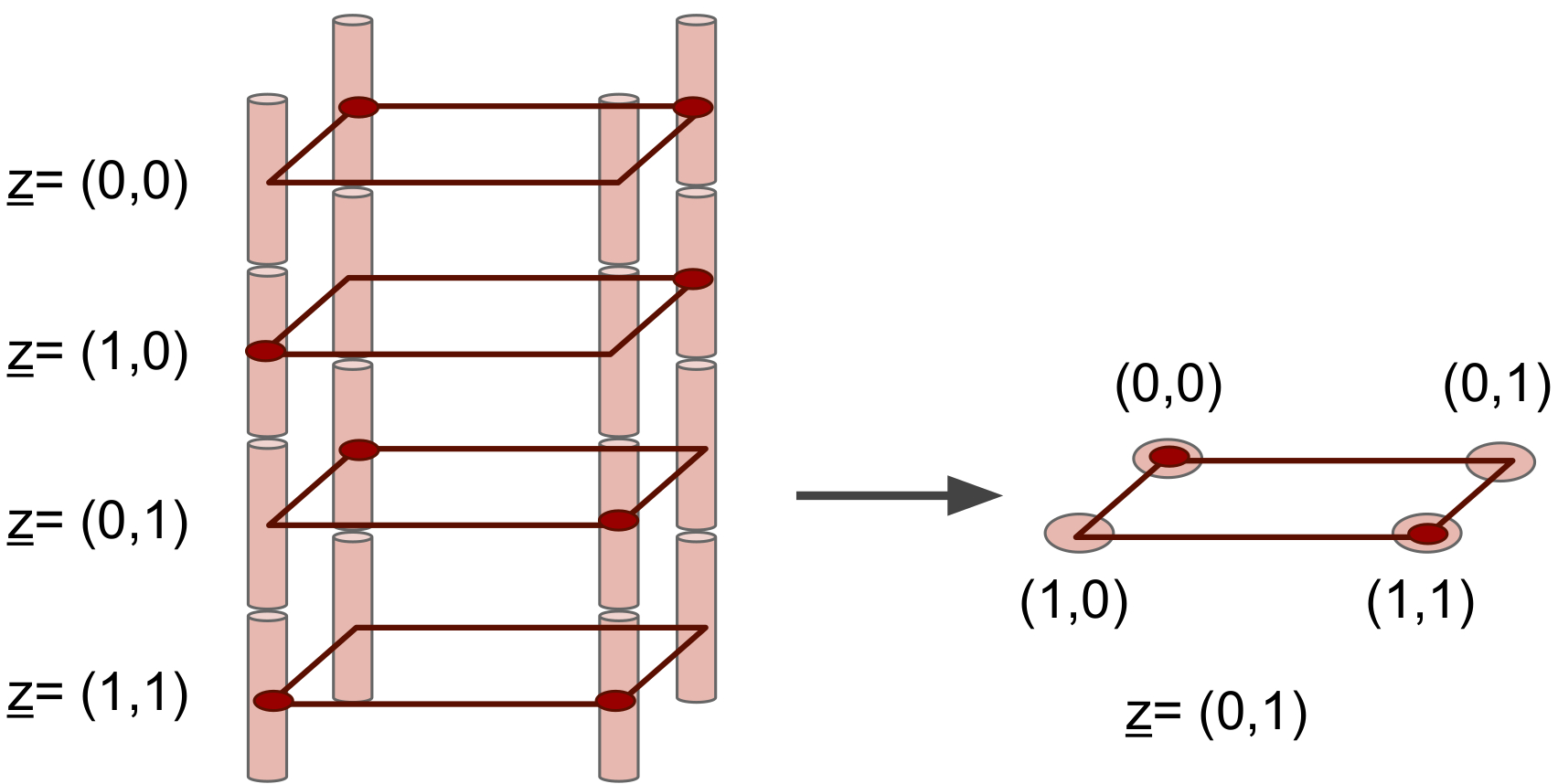
As noted earlier, we will view the Clay code as containing a total of 1616 FqFq symbols, each placed at a distinct vertex of a datacube of size (2×2×4)(2×2×4). In all of the figures that we show, the vertex appears as a small cylinder. We will index each code symbol by the triple
(x,y,z)=(x,y,(z0,z1)),(x,y,z)=(x,y,(z0,z1)),
where {x,y,z0,z1}{x,y,z0,z1} all belong to {0,1}{0,1}, as shown in Figure 15. The figure on the left identifies each plane with a value of z=(z0,z1)z=(z0,z1), whereas the figure on the right identifies the (x,y)(x,y) coordinates of each vertex within the example plane z=(0,1)z=(0,1).
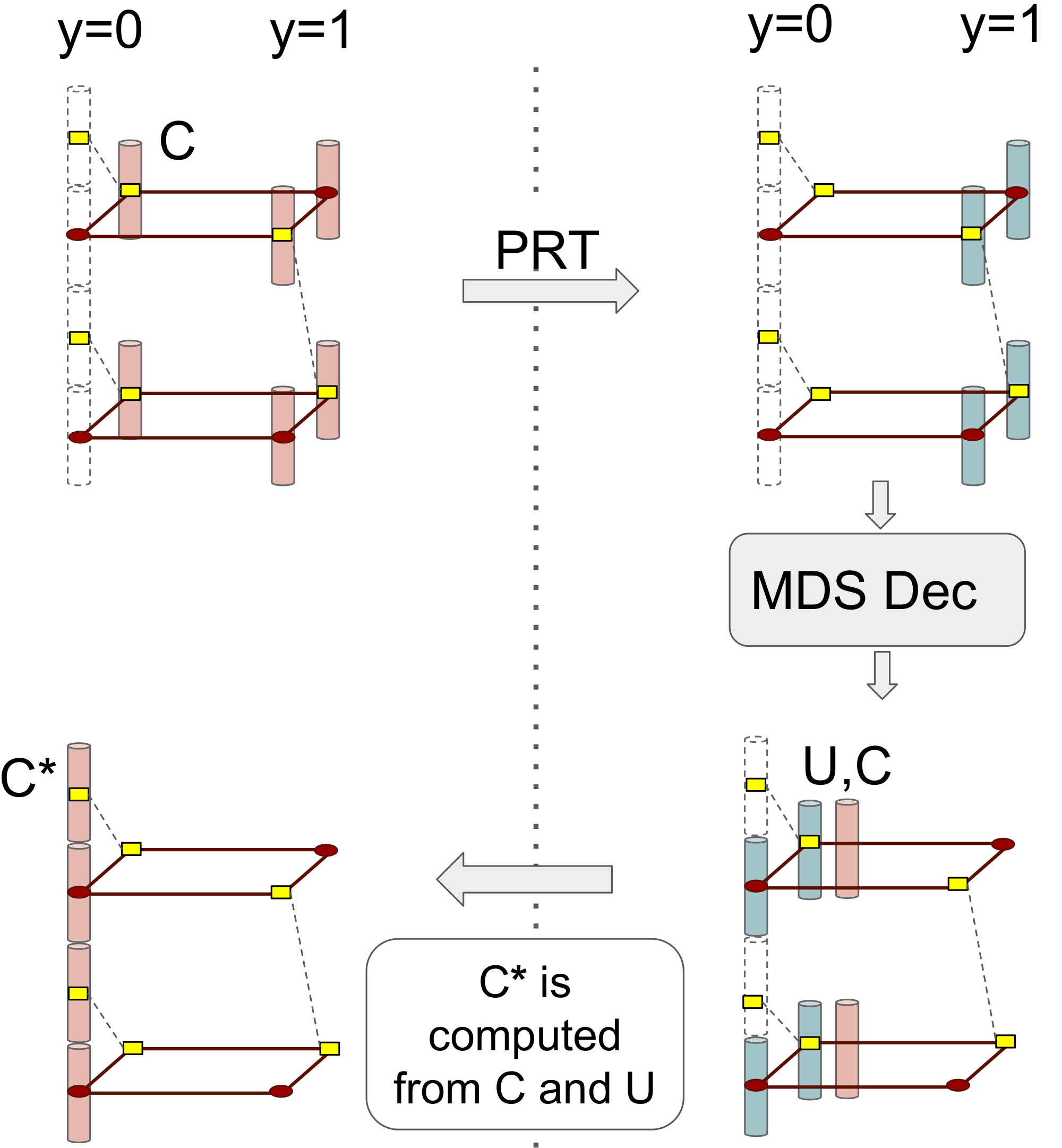
For the purposes of describing the encoding and repair properties of the Clay code, it is convenient to introduce a second datacube of identical dimensions. We will refer to the datacube representing the Clay code itself as the actual datacube and the second datacube just introduced here, as the virtual datacube. Figure 16 shows the two datacubes, with the virtual datacube on the left appearing in blue and the actual datacube appearing on the right in red. The acronyms PFT and PRT appearing in the figure correspond respectively to the expansions pairwise forward transform and pairwise reverse transform. These terms will shortly be explained.
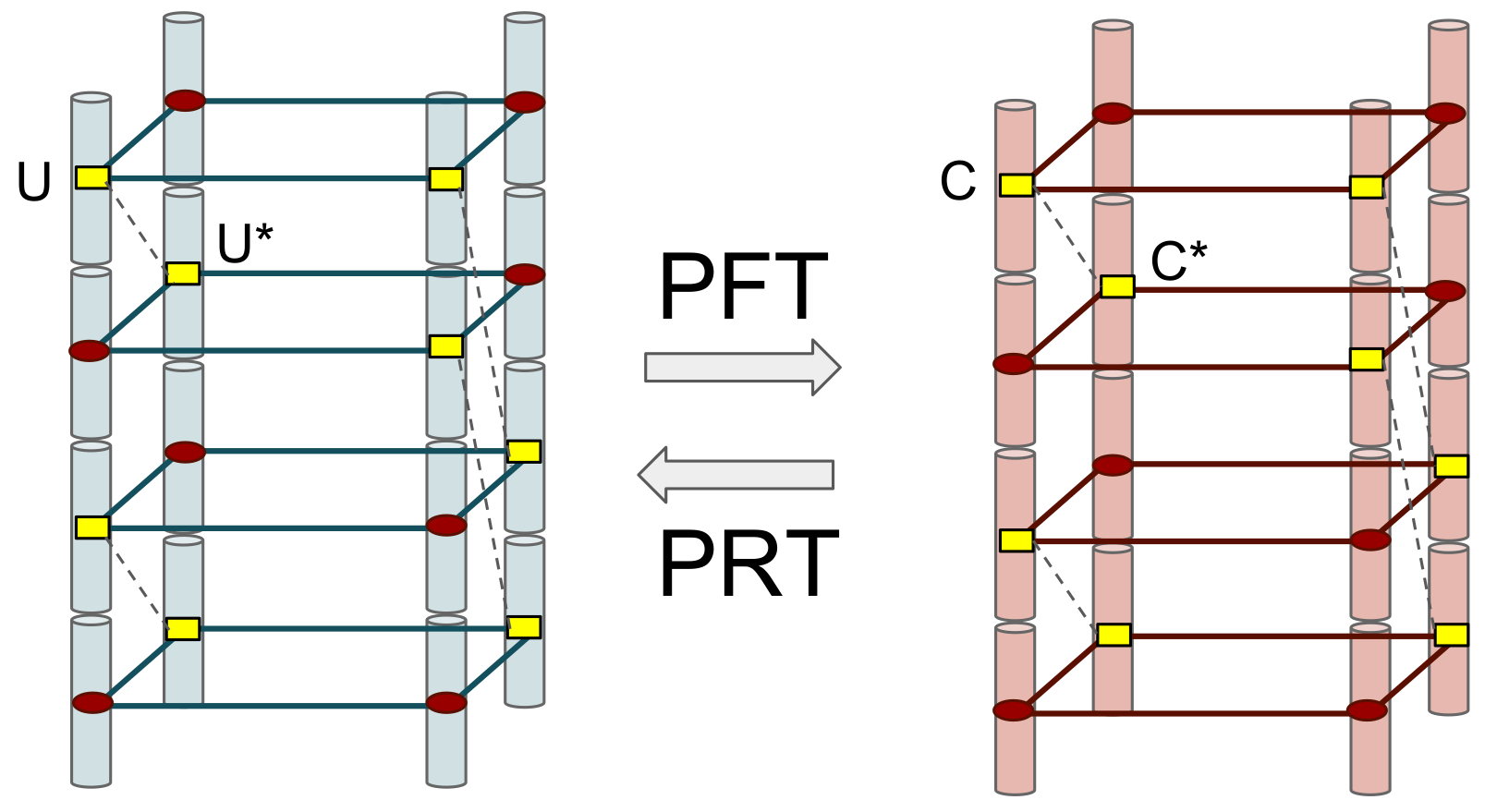
Across the two datacubes, the symbols corresponding to the red dots in the same location are identical. Within each of the datacubes, the symbols associated with vertices that are not colored red, are paired. Example pairings are identified in Figure 16 in yellow and connected by dashed lines. Thus the symbols {U,U∗}{U,U∗} on the left are paired. So are the symbols {C,C∗}{C,C∗} on the right. The indices of the paired symbols are given in general, by:
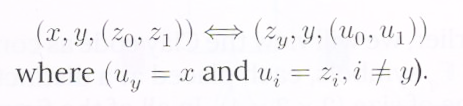
Thus, the two paired symbols share the same yy coordinate and the corresponding vertices lie in the same yy-section of the datacube. The relationship between the pair ![]() on the left and the pair
on the left and the pair ![]() on the right is given by the PFT and PRT as shown below:
on the right is given by the PFT and PRT as shown below:
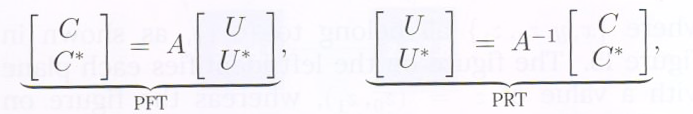
where ![]() is a nonsingular matrix. The matrix AA is required to possess the following additional property: given any two elements in the set
is a nonsingular matrix. The matrix AA is required to possess the following additional property: given any two elements in the set ![]() the remaining two elements can be derived from them. This is equivalent to saying that the matrix
the remaining two elements can be derived from them. This is equivalent to saying that the matrix
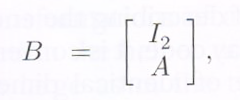
should have the property that any two rows of BB are linearly independent. Here![]() denotes the
denotes the ![]() identity matrix. From this, it follows that given the contents of one datacube, the contents of the other datacube can be fully recovered. The symbols belonging to the virtual datacube possess an important property: the symbols in any given horizontal plane, corresponding to a fixed value of indexing parameter
identity matrix. From this, it follows that given the contents of one datacube, the contents of the other datacube can be fully recovered. The symbols belonging to the virtual datacube possess an important property: the symbols in any given horizontal plane, corresponding to a fixed value of indexing parameter ![]() form an [4,2] MDS code. This naturally, imposes a constraint on the contents of the actual datacube, and is the only constraint placed (in indirect fashion), on the contents of the actual datacube. We will show how this can be used to encode and carry out node repair.
form an [4,2] MDS code. This naturally, imposes a constraint on the contents of the actual datacube, and is the only constraint placed (in indirect fashion), on the contents of the actual datacube. We will show how this can be used to encode and carry out node repair.
Encoding is carried out as described in Figure 17. The four rectangles appearing in the figure represent a top aerial view of the actual (in red) and virtual (in blue) datacubes.
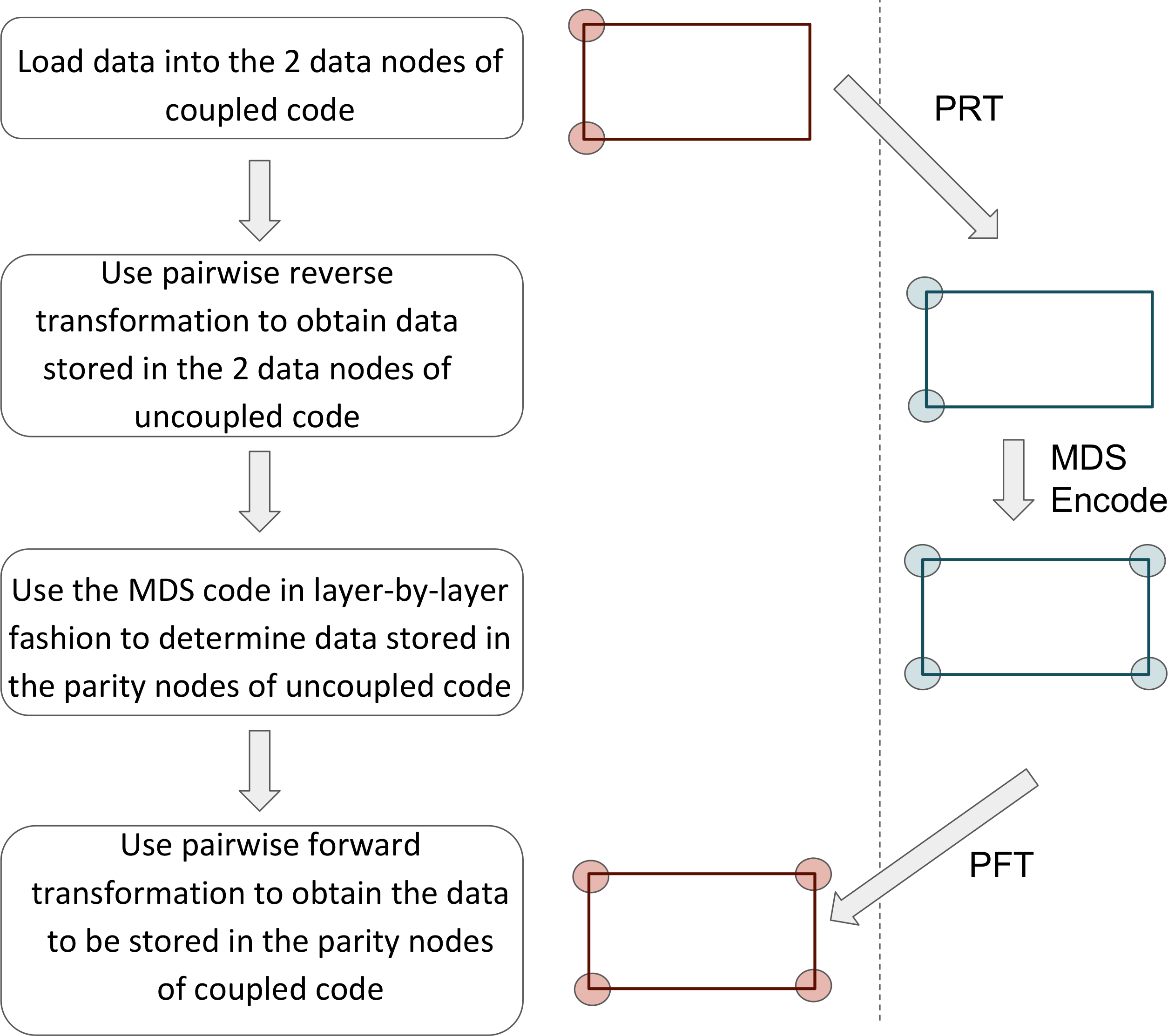
Encoding is carried out as per the steps given below (see Figure 17).
Step 1: The columns of the actual datacube corresponding to nodes having ![]() coordinates
coordinates ![]() are filled with the
are filled with the ![]() message symbols.
message symbols.
Step 2: The PRT is then used to compute the contents of the corresponding nodes in the virtual datacube. This is possible since the two paired symbols always belong to the same ![]() section.
section.
Step 3: In the virtual datacube, we know through Step 2, the values of the 88 symbols belonging to the datacube and corresponding to nodes associated to vertices ![]() The fact that the four symbols in each plane of the virtual datacube (i.e., the 44 symbols corresponding to a fixed value of zz coordinate) form a [4,2][4,2] MDS code, allows the remaining two symbols in that plane and having coordinates
The fact that the four symbols in each plane of the virtual datacube (i.e., the 44 symbols corresponding to a fixed value of zz coordinate) form a [4,2][4,2] MDS code, allows the remaining two symbols in that plane and having coordinates![]() to be determined. Since this procedure can be carried out for each of the 44 planes, at the end of this step, the entire contents of the virtual datacube have been determined.
to be determined. Since this procedure can be carried out for each of the 44 planes, at the end of this step, the entire contents of the virtual datacube have been determined.
In the last and final step, we use the PFT to determine the contents of the actual datacube and corresponding to nodes having vertices ![]() This concludes the encoding process.
This concludes the encoding process.
Node repair is accomplished by carrying out the 33-step procedure described below (see Figure 18). Let us assume without loss of generality that node associated to ![]() has failed.
has failed.
Step 1: We focus on the planes associated to ![]()
![]() There are 22 such planes and we will refer to these as the repair planes. Thus in the present example, the repair planes are the planes corresponding to
There are 22 such planes and we will refer to these as the repair planes. Thus in the present example, the repair planes are the planes corresponding to ![]() namely the planes
namely the planes ![]() Using the PRT and the known contents of the actual datacube associated to vertex set
Using the PRT and the known contents of the actual datacube associated to vertex set ![]() the contents of the virtual datacube and associated to the same vertex set
the contents of the virtual datacube and associated to the same vertex set ![]() in the repair planes can be determined.
in the repair planes can be determined.
Step 2: The MDS code binding the 44 symbols in the repair planes of the virtual datacube is used to decode the remaining symbols in the repair planes.
Step 3: the symbols in the repair planes and associated to the red dots are the same in the virtual and actual datacubes. Thus we have recovered 22 of the lost symbols in the failed node (of the actual datacube), namely the symbols associated to vertex sets:
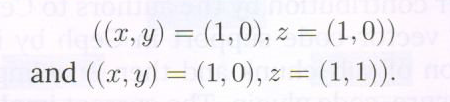
We also have access to the symbol pairs ![]() associated to vertex sets
associated to vertex sets
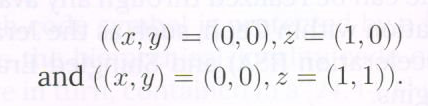
Using these, the corresponding symbols ![]() can be determined and these are precisely the remaining two symbols in the failed node, namely the symbols associated to vertex sets:
can be determined and these are precisely the remaining two symbols in the failed node, namely the symbols associated to vertex sets:
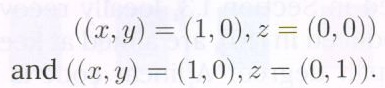
This concludes the repair process.
In a joint collaborative effort involving the University of Maryland, NetApp and the Indian Institute of Science, Clay codes have been implemented in an open-source distributed storage system called Ceph [26] and evaluated over an AWS (Amazon Web Services) cluster. This effort can be found described in [25]. It is planned to have the Clay code made available as an erasure code plugin in the upcoming Nautilus release [27] of Ceph. An earlier contribution by the authors to Ceph involved enabling vector-code support in Ceph by introducing the notion of sub-chunk and then enabling Clay code as an erasure-code plugin. The current implementation leaves open the choice of scalar MDS building block, i.e., the code can be realized through any available MDS implementation within Ceph, such as the Jerasure, Intel Storage Acceleration (ISA) and Shingled Erasure Code (SHEC) plugins.
As mentioned in Section 1.3, locally recoverable codes (LRCs), introduced in [10], are aimed at keeping to a low level, the repair degree. A linear code is systematic if the kk message symbols are explicitly present among the nn code symbols. An (n,k,r)(n,k,r) LRC CC over a field FqFq is a systematic [n,k][n,k] linear block code having the property that every message symbol ctct, t∈[k]t∈[k] can be recovered by computing a linear combination of the form
ct=∑j∈Stajcj, aj∈Fq,(4)(4)ct=∑j∈Stajcj, aj∈Fq,
involving at most rr other code symbols cj,j∈Stcj,j∈St. Thus the set StSt in the equation above has size at most r.r. The minimum distance of an (n,k,r)(n,k,r) LRC must satisfy the bound
dmin≤(n−k+1)–(⌈kr⌉−1).dmin≤(n−k+1)–(⌈kr⌉−1).
An LRC whose minimum distance satisfies the above bound with equality is said to be optimal. The class of pyramid codes [28] are an example of a class of optimal LRCs.
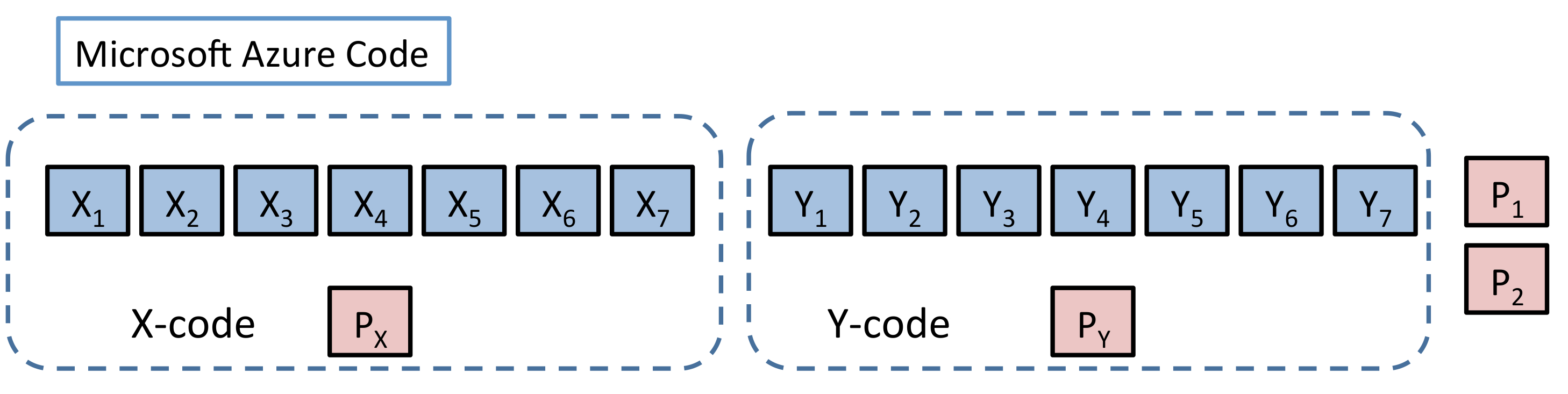
Figure 19 shows the (n=18,k=14,r=7)(n=18,k=14,r=7) LRC employed in conjunction with Windows Azure [29] and which is related in structure, to the pyramid code. The dotted boxes indicate a collection of symbols that satisfy an overall parity check. This code has minimum distance 44 which is the same as that of the [n=9,k=6][n=9,k=6] RS code appearing in Figure 20.
In terms of reliability, the codes are comparable as they both have the same minimum distance dmin=4dmin=4. In terms of repair degree, the two codes are again comparable, having respective repair degrees of 77 (Azure LRC) and 66 (RS). The big difference is in the storage overhead, which stands at 1814=1.291814=1.29 in the case of the Azure LRC and 96=1.596=1.5 in the case of the [9,6][9,6] RS code. This difference has reportedly saved Microsoft millions of dollars [30].
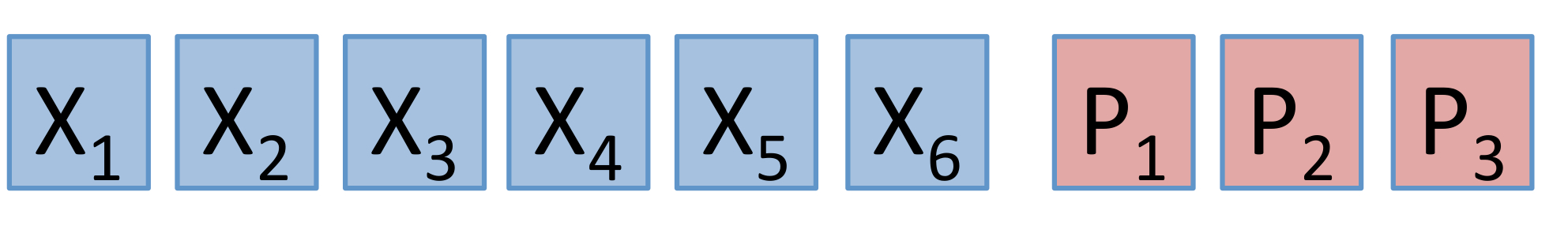
An LRC in which every code symbol can be recovered from a linear combination of at most rr other code symbols is called an all-symbol LRC. A construction for optimal all-symbol LRCs can be found in [31]. The codes in the construction may be regarded as subcodes of RS codes. An example is shown in Figure 21. As was noted in Section 1.1, code symbols in an RS code may be regarded as values of a polynomial associated with the message symbols. The construction depicted in Figure 21, is one in which code symbols are obtained by evaluating a subclass of polynomials. This subclass of polynomials has the property that given any code symbol corresponding to the evaluation f(Pa)f(Pa), there exist two other code symbols f(Pb),f(Pc)f(Pb),f(Pc) such that the three values lie on straight line and hence satisfy an equation of the form
uaf(Pa)+ubf(Pb)+ucf(Pc)=0.uaf(Pa)+ubf(Pb)+ucf(Pc)=0.
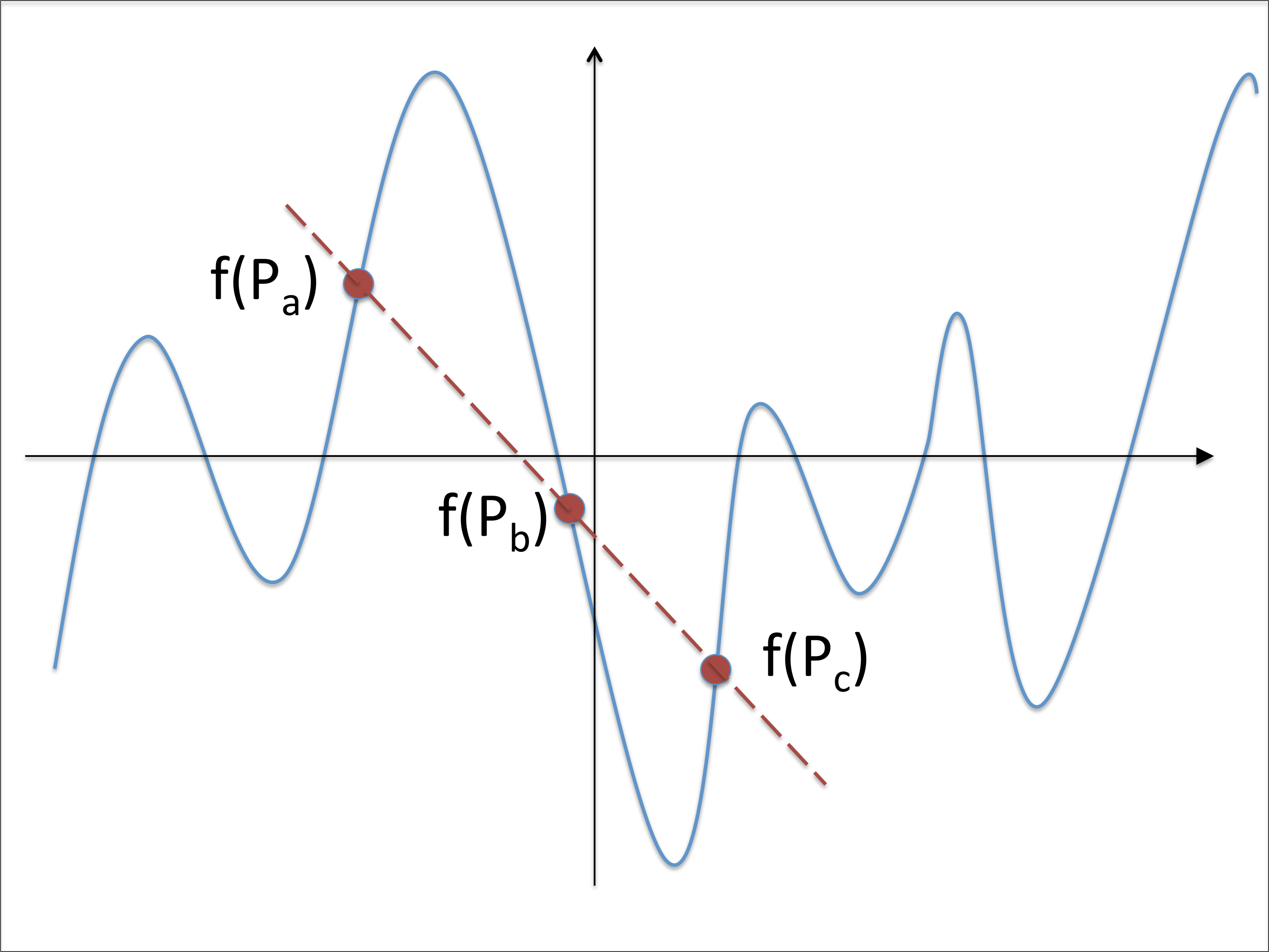

Thus this leads to an LRC with r=2r=2. This construction can be generalized to any rr and the resultant codes turn out to be optimal.
One disadvantage of an LRC is that the idea of an LRC is not scalable. Consider an [24,14][24,14] linear code which is made up of the union of 66 disjoint [4,3][4,3] ‘local’ codes (see Figure 22 on the left). These local codes are single parity check codes and ensure that the code has locality 33. However, if there are 22 or more erasures within a single local code, then recovery is not possible. Codes with hierarchical locality [32] (see Figure 22 (right)) seek to overcome this by building a hierarchy of local codes to ensure that in the event that a codeword in the lowest level fails, then the local code at the next level can take over. The local codes at higher levels have a minimum distance that permits recovery from more than one erasure.
Hierarchical codes present one method of designing a code with locality that can recover from more than one erasures. There are other approaches as well. Availability codes [33], [34] cater to the situation when a node containing a code symbol that it is desired to access is unavailable as the particular node is busy serving other requests. To handle such situations, an availability code is designed so that the same code symbol can be recovered in multiple ways, as a linear combination of a small subset of the remaining code symbols. The binary product code shown in Figure 23 is one example of an availability code. The symbols PP shown in the figure represent respectively either a row or column parity. Here each code symbol can be recovered in 33 distinct ways: directly from the node storing the code symbol or else by computing the sum of the remaining entries in either the row or the column containing the desired symbol.
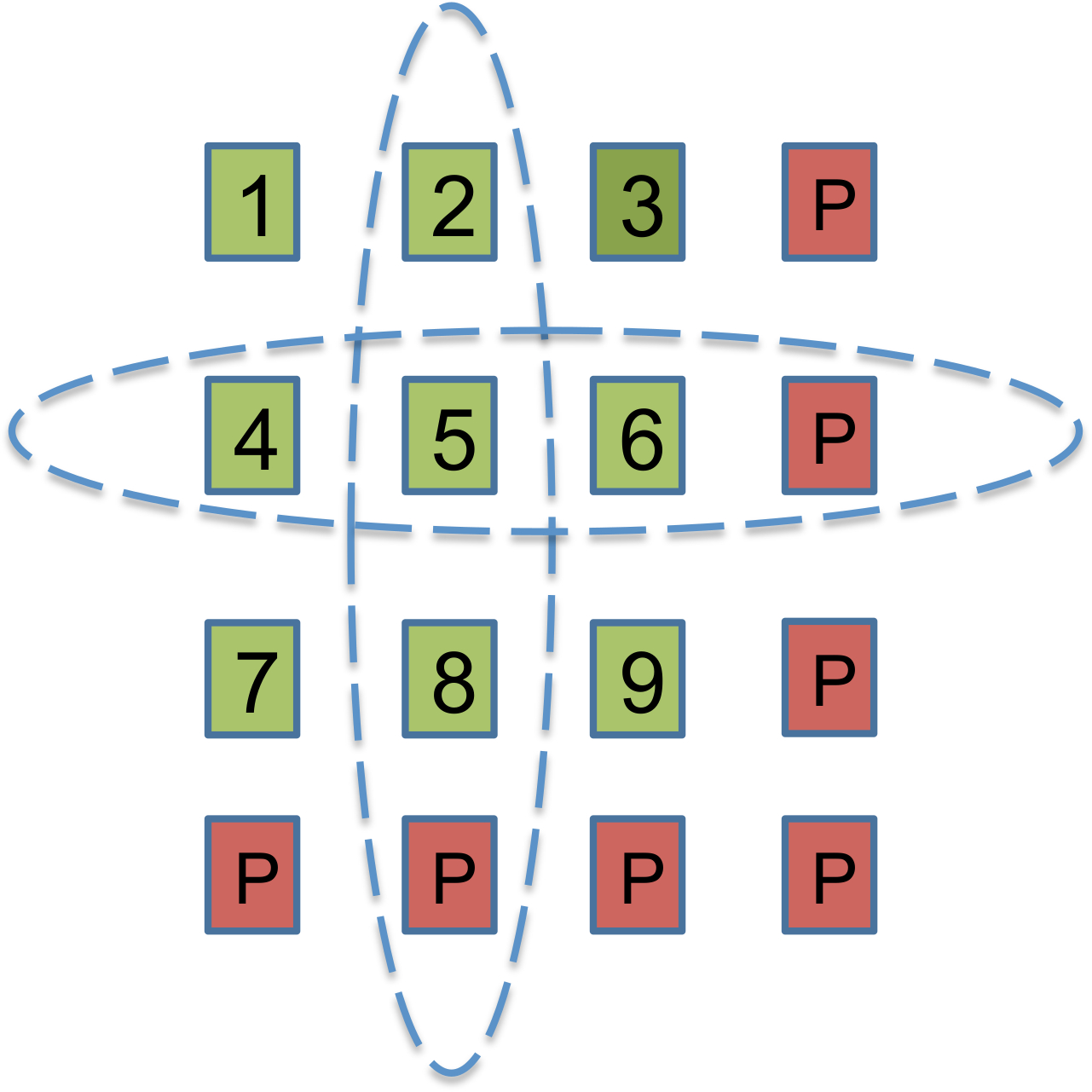
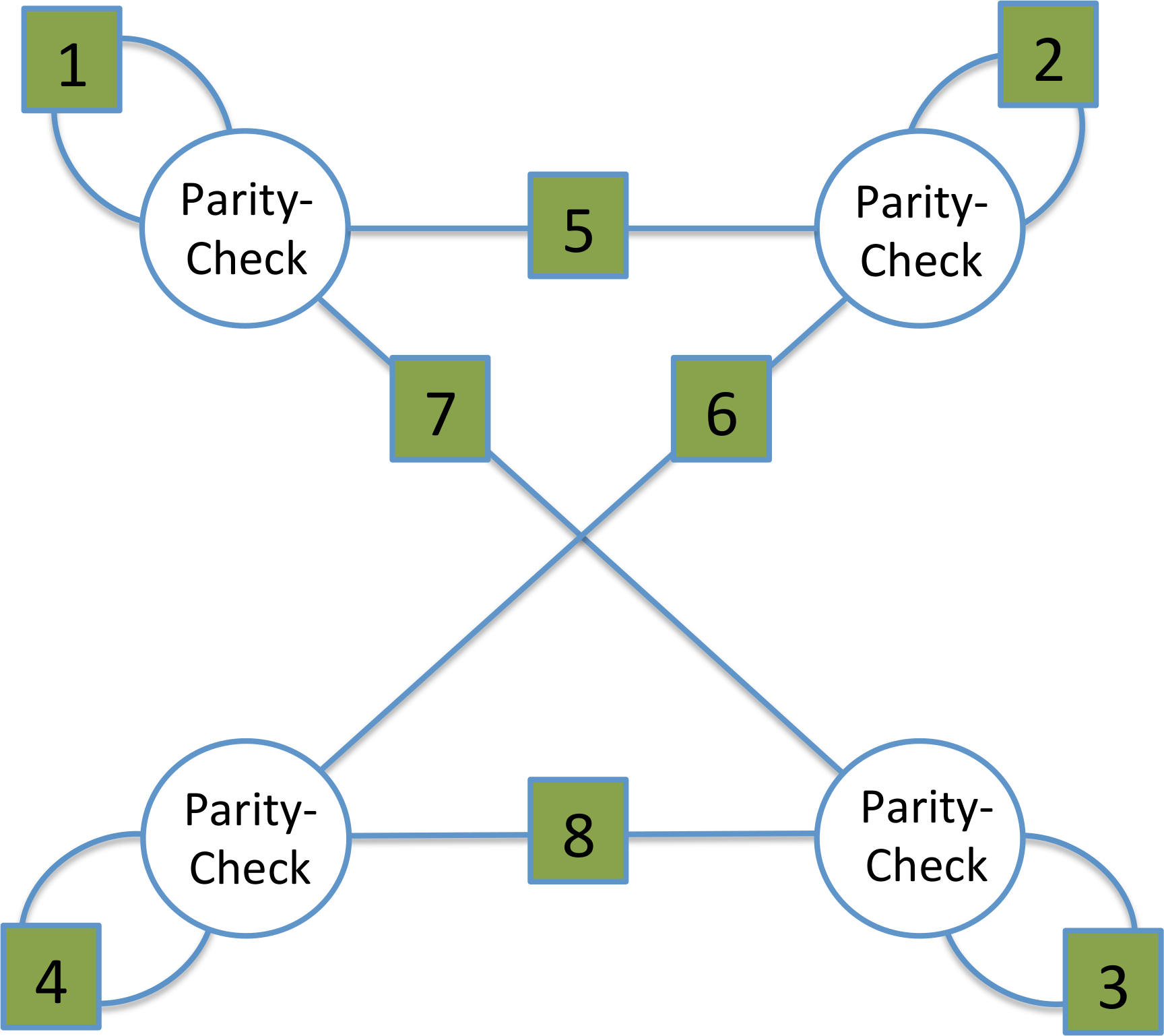
The most general approach, and the one that imposes the least constraint in terms of how recovery is to be accomplished is sequential recovery [35], [36]. An example of a code with sequential recovery is shown in Figure 24. In the figure, the numbers correspond to the indices of the 88 message symbols. The 44 vertices correspond to the 44 parity symbols. It can be seen that if message symbols 11 and 55 are erased, and one chooses to decode using locality, then one must first decode 55 before decoding symbol 11.
There is a class of codes known as codes with local regeneration that provide the benefits of both reduced degree and reduced repair bandwidth (see Figure 25). For details the reader is referred to [37, 38, 39].
Erasure coding for distributed storage enables the reliable storage of very large amounts of data with far less overhead in comparison to replication, while efficiently handling node repairs. Over the past decade, this area has seen extensive research and many exciting codes have been developed as a result. The adoption of LRCs into the Microsoft Azure storage which resulted in significant cost savings, is one of the big success stories along this line of research. Although there are practical implementations of regenerating codes in the literature, regenerating codes are yet to make their way into a production cluster. The planned incorporation of the Clay code into the Nautilus release of Ceph, is an important step in this direction. There remain some open theoretical problems that are also of interest to industry. An example of this is the problem of constructing (vector) MDS codes which are repair bandwidth-efficient, yet offer a low sub-packetization level so as to mitigate the problem of fragmented read.
The authors would like to acknowledge support from the J. C. Bose National Fellowship, the US National Science Foundation under Grant No. 1421848 as well as from the NetApp University Research Fund, a corporate advised fund of the Silicon Valley Community Foundation.
