
In recent times, computational modeling of narratives has gained enormous interest in fields like Natural Language Understanding (NLU), Natural Language Generation (NLG), and Artificial General Intelligence (AGI). There is a growing body of literature addressing understanding of narrative structure and generation of narratives. Narrative generation is known to be a far more complex problem than narrative understanding [20].
Narratives are characteristic of human semantic communication. A narrative represents a coherent perspective about a semantic universe, like a story or a current event. The human mind is known to be much more amenable for processing narratives, rather than disjoint facts and figures [10]. Across cultures of the world, and throughout history, it is common to see narratives as the basic tool for social communication, driving the formation of collective worldviews and social cognition.
A narrative comprises of a basic structure represented by a sequence of events, and a story-line or exposition that emerges out of such sequencing [9], [16]. Formally, the sequence of events that forms the basic structure is called the fabula, and the exposition that emerges from it, is called the syuzhet. A narrative is also made up of key actors that play a role in the events. The syuzhet creates a specific story-line, by representing the evolution of attributes of actors, and relationships among the actors across the fabula.
It is important to note the difference between the “story-line” or the exposition of a narrative, and the underlying story itself. A story represents the set of all events that have happened and all the actors and all the relationships between them. The story-line of narrative on the other hand, is a specific perspective on the story. A story can be conveyed with more than one narrative, representing different perspectives. Similarly, two different stories may be narrated using very similar story-lines, showing similarity in their underlying trope or semantic structure.
Table 1 shows narrations of two popular Aesop’s fables, that brings out a common underlying trope – that of gaining something by means of deceit, which forms the underlying semantic structure of both stories.
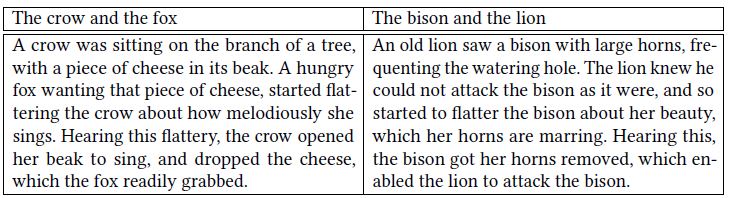
Table 1. Two story-lines depicting a common underlying trope of gaining by means of deceit.
2 NARRATIVE GENERATION
Goal of Narrative Generation is to aid humans in authoring improved narrations or produce automated better narrations. It has far-reaching applications in the field of Medicine, Education, Literature and Journalism. A narrative generated from the vital parameters of a patient is known to aid better decision making when compared to information in tabular and graphical data. In Portet et al. [18], an attempt has been made to generate narratives from neonatal intensive care data. A narrative about a patient’s condition is easy to comprehend, visualize and triggers quick decision to offer appropriate medication to the patient.
In schools for children with special communication needs, narratives about what such children truly want to express can be constructed using narrative generation. In Tintarev et al. [25], a system is proposed that automatically creates a personal narrative from sensor data and other media (photos and audio) which can be used by children with complex communication needs in schools to support interactive narrative about personal experiences.
Screen writers in commercial entertainment can use diverse coherent narratives generated from a corpus as source of inspiration to author novel stories. In Lönneker et al. [14], models and approaches have been proposed for automated creation of fiction or “literary artifacts” that might take the form of prose, poetry or drama. Models achieve combination of events and generation of plots which are difficult for a human author to conceive and resulting narratives can be a trigger for the author to think and pursue a new story or a fundamentally different plot to convey a story.
In the field of journalism, an apt technical narration of facts makes a large difference in getting news to proliferate. Often news is backed by statistical data and there is a need to form a narrative out of it for readers to make a quick sense of the news the data is meant to convey. In Dörr [6], a study has been done at a technical level, to address whether natural language generation can produce news. The study also addresses the economic potential of NLG in journalism as well as indicating its institutionalization on an organizational level.
One of the earliest story generation system was TALE-SPIN [3] in 1981. In this system, goals were set for the characters and the recorded path of characters constituted the generated narrative. TALE-SPIN was a pioneer in NLG, and its approach for problem-solving, became the de facto standard model for other AI researchers working on storytelling and related areas [28].
Some of the prominent story-generation systems in recent times, are BRUTUS [5], MINSTREL [26] and MEXICA [27]. y Pérez and Sharples [28] provides a detailed evaluation of these three systems.
BRUTUS is a Prolog-based system which generates stories on predefined themes. The themes are primarily of betrayal, self-deception and other literary themes. At a high-level, there are three processes that characterize this system: instantiation, development of plot, and expansion of story grammar involved in story generation. Instantiation is achieved through story-frames or story-themes. Story-frame captures the characters and their goals and story-theme sets the theme of the story. The plot generation is achieved through pro-active actions or actions as per the plan and reactive actions by the characters and the story generation stops when there are no actions that can be generated. The final output is generated through story-grammar expansion where lexical constructs are chosen and text is generated. BRUTUS is the recent of the three systems and reuses known methodologies.
“Simple Betrayal” a story developed by BRUTUS: Dave Striver loved the university. He loved its ivy-covered
clocktowers, its ancient and turdy brick and its sun-splashed verdant greens and eager youth. He also loved the fact that the university is free of the stark unforgiving trials of the business world – only this isn’t a fact: academia has its own tests, and some are as merciless as any in the marketplace. A prime example is the dissertation defense: to earn the Ph.D., to become a doctor, one must pass an oral examination on one’s dissertation.
Dave wanted desperately to be a doctor. But he needed the signature of three people on the first page of his dissertation, the priceless inscription which, together, would certify that he had passed his defense. One, the signatures had to come from Professor Hart. Well before the defense, Striver gave Hart a penultimate copy of his thesis. Hart read it and told Striver that it was absolutely first-rate, and that he would gladly sign it at the defense. They even shook hands in Hart’s book-lined office. Dave noticed that Hart’s eyes were bright and trustful, and his bearing paternal.
At the defense, Dave thought that he eloquently summarized Chapter 3 of his dissertation. There were two questions. One from Professor Rodman and one from Dr. Teer; Dave answered both, apparently to everyone’s satisfaction. There were no further objections. Professor Rodman signed. He slid the tome to Teer; she too signed, and then slid it in front of Hart. Hart didn’t move. “Ed?” Rodman said. Hart still sat motionless. Dave felt slightly dizzy. “Edward, are you going to sign?” Later, Hart sat alone in his office, in his big leather chair, underneath his framed Ph.D. diploma
MINSTREL is the first computerized complex story generation system which writes short stories about King Arthur and his knights of the round table. It takes into account both the author level goals or plans and character level goals. Author level goals are achieved through author schemas like a theme or including suspense in the story. Character level goals are represented through schemas like satisfying hunger, finding romantic partner etc. which are linked to form scenes. The important aspect of MINSTREL is creativity through Transform Recall Adapt Methods (TRAMs). If character goal is trivial it is transformed, based on the transformation events are recalled and adapted to the story being generated to achieve novel introduction, theme and denouement scenes. MINSTREL is known to produce novel outputs and considered to be an important advancement on TALE-SPIN.
“The Vengeful Princess” a story developed by MINSTREL: Once upon a time there was a lady of the court
named Jennifer. Jennifer loved a knight named Grunfeld. Grunfeld loved Jennifer.
Jennifer wanted revenge on a lady of the court named Darlene because she had the berries which she picked in the woods and Jennifer wanted to have the berries. Jennifer wanted to scare Darlene. Jennifer wanted a dragon to move towards Darlene so that Darlene believed it would eat her. Jennifer wanted to appear to be a dragon so that a dragon would move towards Darlene. Jennifer drank a magic potion. Jennifer transformed into a dragon. A dragon moved towards Darlene. A dragon was near Darlene.
Grunfeld wanted to impress the king. Grunfeld wanted to move towards the woods so that he could fight a dragon. Grunfeld moved towards the woods. Grunfeld was near the woods. Grunfeld fought a dragon. The dragon died. The dragon was Jennifer. Jennifer wanted to live. Jennifer tried to drink a magic potion but failed. Grunfeld was filled with grief.
Jennifer was buried in the woods. Grunfeld became a hermit
MEXICA generates stories about former inhabitants of Mexico city. It uses engagement and reflection approach to creativity and it is the first story generation system to consider cognitive account in writing. With the story context as a cue, in the engagement process the content is generated and there are no specific goals set for the characters. In the reflection process the logical flow, novelty and coherence of the story is ensured. The cycle ends when fixed number of actions have been retrieved or when there are no actions resulting in a cue to continue. In this way this is the first system which does not use pre-defined structures and ensures interestingness of the story being generated.
“The Lovers” a story generated by MEXICA: Jaguar knight was an inhabitant of the great Tenochtitlan.
Princess was an inhabitant of the great Tenochtitlan. From the first day they met, Princess felt a special affection for Jaguar Knight. Although at the beginning Princess did not want to admit it, Princess fell in love with Jaguar Knight. Princess respected and admired artist because artist’s heroic and intrepid behavior during the last Flowery-war. For long time Jaguar Knight and Princess had been flirting. Now, openly they accepted the mutual attraction they felt for each other. Jaguar Knight was an ambitious person and wanted to be rich and powerful. So, Jaguar Knight kidnapped artist and went to Chapultepec forest. Jaguar Knight’s plan was to ask for an important amount of cacauatl (cacao beans) and quetzalli (quetzal) feathers to liberate artist. Princess had ambivalent thoughts toward Jaguar Knight. On one hand Princess had strong feelings towards Jaguar Knight but on the other hand Princess abominated what Jaguar Knight did. Suddenly the day turned into night and after seconds the Sun shone again. Princess was scared. The Shaman explained to Princess that Tonatiuh (the divinity representing the Sun) was demanding Princess to rescue artist and punish the criminal. Otherwise Princess’s family would die. Early in the morning Princess went to Chapultepec forest. Princess thoroughly observed Jaguar Knight. Then, Princess took a dagger, jumped towards Jaguar Knight and attacked Jaguar Knight. Jaguar Knight was shocked by Princess’s actions and for some seconds Jaguar Knight did not know what to do. Suddenly, Princess and Jaguar Knight were involved in a violent fight. In a fast movement, Jaguar Knight wounded Princess. An intense haemorrhage arose which weakened Princess. Jaguar Knight felt panic and ran away. Thus, while Tlahuizcalpantecuhtli (the god who affected people’s fate with his lance) observed, Princess cut the rope which bound artist. Finally, artist was free again! Princess was emotionally affected and was not sure if what Princess did was right. Princess was really confused. The injuries that Princess received were very serious. So, while praying to Mictlantecuhtli (the lord of the land of the dead) Princess died.
Narrative structure understanding is the key to construct computational models. While narrative generation is about deriving engaging stories creatively based on a corpus, understanding has subtle applications. Studying corpora of narratives and understanding different aspects is critical to construct a well-defined model. We will first review the use-cases solved by narrative understanding and later delve into general narrative computational models.
In Elson et al. [8], social networks are extracted from literary fictions, and nineteenth-century British novels and serials. It is a commonly held belief that literary works represent the social world of the time when the novel was written. By studying dialogue patterns in novels social networks is derived and with that the characterization of novels. In Danescu-Niculescu-Mizil and Lee [4], fictional literary works are studied to understand the coordination of linguistic style in dialogues. Often during conversations we tend to adapt to each others style, which is termed as Chameleon effect. These kind of studies are helpful in understanding social networks.
In Alharthi et al. [1], a recommender system for books based on the content is proposed. It is observed reading books by people has reduced during recent times. Book reading is statistically known to promote better mental health and particularly reading fictional books stimulate profound social communication. There are two approaches to recommender systems: Collaborative Filtering (CF), which are based on ratings given by other readers, and Content Based (CB) recommendations based on the actual content of the book. In situations where we do not have sufficient ratings on a book which is more often, content based systems are more useful.
In Serban et al. [22], a comprehensive survey of copora to build data driven dialog systems is presented. Dialogue systems are very useful in machine to human communication. Till the recent past these systems were built based on expert knowledge and significant engineering. With availability of exhaustive data-sets in public domain, state-of-art computational power and new machine learning models like neural network architectures, there are immense possibilities of building dialogue systems from corpora.
In Ashok et al. [2], a quantitative analysis of successful novels based on writing style is proposed. The answer to whether a novel will be successful or not has been a qualitative approach through expert opinion and experience of publishers. In this work various aspects of style are quantified and used to analyze successful from unsuccessful novels backed by empirical data of prominence from popular book selling websites.
In He et al. [12], a supervised machine learning approach for attributing utterances to the characters in a novel is proposed. Relating utterances to a character is considerably challenging even for a human reader. The solution has applications like generating high-quality audio books without human networks and analysis of dialogues is useful for the study of social interactions.
Writing essays is an important part of education for children. In Somasundaran et al. [23], an automatic way of analyzing narrative quality written by children is proposed. Assessment of different quality dimensions of a written narrative is non-obvious, since creative ways children can use to write are unbounded. With U.S. Common Core State Standards rubric 942 essays were annotated and inter-annotator agreement was used to understand the reliability of scoring.
Above were some example use-cases that were addressed using narrative modelling. In next section, we will review core narrative models.
The most recent and popular computational model of narratives is the Story Intention Graph (SIG) [7], [15]. SIG model captures structure of a narrative in great detail. The model is composed of three interconnected layers – the Text, the Timeline and the Interpretative layer. Narratives are modeled through these basic units. With the patterns of SIG encodings, narratives are categorized in to 80 pre-defined scenario classes like “Gain,” “Promise Broken,” “Unintended Harm,” etc. The scenario classes represent narrative tropes in terms of SIG relations. SIG captures both the timeline of events in the narratives and and the relationship between the actors or entities in the narrative. Analogical similarity is deduced with combinations of layers in the encoding. Three are three suggested analogy detection approaches. The first is Propositional Similarity, where just the timeline is used. The second is Static Analogy, a top-down approach, where analogy is inferred by mapping encoding with one of pre-defined scenario patterns. The third is Dynamic Analogy, a bottom-up approach, where analogy is inferred by largest isomorphic subgraph. Scheherazade1 is a freely available application program, to encode stories in the form of SIGs. SIG is a good formal model to represent narratives and it has to constructed manually from the text using the tool.
In Halpin et al. [11], a model is proposed to analyze recall of events and the sequencing in rewritten stories by children. The model was devised to develop a system called “Story Station” to provide guidance in writing stories to children aged between 10-12 years. The computational model compares stories by finding equivalence of lemmatized tokens of events, using WordNet and events order. The merit of rewritten stories is decided by the semantic nearness of recalled events and reproduction of event sequences. Rewritten stories were rated as Excellent, Good, Fair and Poor. The story was rated excellent, when the point of the story and all important sequences are reproduced. Good rating was assigned for stories when main events and links were reproduced. Fair rating was assigned for stories when a major chunk of the story is missing and poor when substantial amount of the plot is missing. A corpus of 103 stories rewritten by children were used to evaluate the model.
In Miller et al. [17], relationship between entities is computed by finding the similar events in which they appear. Finding the similarity between entities is termed as alignment. Events are extracted and event sets are created manually. Similarity between events is found with the abstract hypernym of tokens appearing in events text and entities appearing in similar events are tagged to be related. An adjacency matrix of entity relationships is created. The adjacency matrix results in a graph of entities as nodes and edges as hypernym relation. From these graphs, using network analysis approaches, similarity between all entities of narrative document is computed.
Reiter et al. [21] presents an unsupervised and automated narrative structure discovery approach. It was evaluated on ritual description and folktale narratives corpus. A narrative is represented as a graph with entities as nodes and edges as relationship between them. The story is first represented as a sequence of events, and entities appearing in a single event are tagged to be related. Model is constructed using FrameNet for event re-construction, co-reference resolution to relate entities across narrative document and WordNet sense to compare events at a higher abstract level. Three alignment algorithms are suggested: Sequence alignment to align chains of sequences from narrative documents, Graph based predicate alignment to align by similar predicate-argument structures of events from narrative documents and Bayesian model merging to align using Hidden Markov Models (HMM) in event sequences from narrative documents.
1Scheherazade SIG tool: http://www.cs.columbia.edu/~delson/software.shtml
In the study of narratives, the structure of a narrative can be described in terms of two aspects [16]:
(1) Content of the narrative often called the story, fabula or histoire
(2) Exposition or style in which the story is narrated often called discourse, or discours or syuzhet.
Fabula. Fabula is the chain of events (actions, happenings) along with existents (actors, characters, items in the setting). Characters in a fabula can have traits (physical, moral, etc). These traits can evolve or change over the course of the narrative. Traits can be derived from certain cues in the text or from the actions the character performs. They can also be derived by association with social rules. Or alternatively, a fabula can be thought of as a chronological ordering of events in the story. It contains all the factual elements of the story ordered by time of occurrence of the events.
Syuzhet. Syuzhet refers to how the events of the story are narrated. The syuzhet is in turn, modeled as comprising of two components: the plot and the exposition. The plot refers to the main “story structure” of the narrative, while the exposition refers to the style in which the story is narrated. Style of narration here can be described under various characteristics. A few of them are listed below:
(1) Narrator Identity – The narrator’s identity is the answer to the question “Who speaks?” in a narrative. If my friend is telling me a story, he/she is the narrator
(2) Narrative Distance – A narrator can vary the narrative distance between his/herself and the characters in the narrative using different forms of speech. Eg: Indirect, Narrated and quotation
(3) Narrator Perspective – A narrator’s perspective or the point-of-view is the answer to the question “Who sees?”. A narrator can take the perspective for a character for parts of the narrative or he/she can be omniscient, “seeing” into the minds of one or more characters
(4) Narrative Levels – The narrative could have multiple narratives embedded in one another like in case of The Thousand and One Nights or we can also have multiple narratives that weave in and out of each other.
(5) Narrative Order – The order in which the events in the fabula are narrated. For example, flashbacks, retrograde, etc. There are seven ways in which we can draw relation between the order of narration in the discourse and the order of events in the fabula
A narrative can be modeled by trying to analyze either the fabula or the syuzhet or both.
5.1 Bag-of-actors Model
Srivatsa and Srinivasa [24] present an abstract “bag-of-actors” document model which is meant for comparing, indexing and retrieving documents based on their narrative structure. This model is based on resolving the main entities or actors in the plot, and the corresponding actions associated with them.
In this model, the plot of a narrative is essentially narrowed down to the following elements: the primary actors in the plot, and the set of expressions or actions that are performed by the actors. In other words, the essence of a plot is distilled to: who are involved in the plot and what do they do.
The similarity computation is modeled as a maximal matching problem between tokens of the first expression and the second. It is implemented in the form of a greedy knapsack algorithm. The model first computes the similarity between two expressions simEx. Using this simEx, it then computes the similarity between two actors simact. Finally, it computes the similarity between two narratives simN using the simact
Actors and expressions are compared using the WordNet LIN similarity measure. LIN gives a similarity score of 1 when the provided tokens match the term and the sense. When the terms and/or sense do not match, LIN returns a similarity measure based on the information content (IC) of the respective words and that of their least common subsumer (LCS) in the hypernym tree that subsumes them. Least Common Subsumer of two concepts A and B is “the most specific concept which is an ancestor of both A and B”.
Identification of actors and expressions are performed by parsing the document on a sentence level. Actors across sentences are linked using the Stanford NLP neural co-reference resolution system. Expressions are extracted from constituency parse trees of sentences. Constituency parse trees break sentences into sub-phrases with words as leaf nodes and phrase types as inner nodes.
The larger problem is to retrieve candidate documents for comparison from a corpus of documents. Given an input document with a story, it is not feasible to compare it pairwise against all documents in a large corpus. In order to address this, this paper proposes a variant of the conventional inverted index model for indexing documents, called the hypernym index.
An inverted index is in the form of a “postings list”, where each element in the list represents a term and points to a set of documents that contain the term.
Given a query document, the method uses the hypernym index to retrieve candidate documents that are likely to be similar in terms of their narrative. In order to do this, the query document dq is parsed to obtain all the sense-disambiguated tokens representing expressions. The hypernym trees for each of the tokens obtained are then constructed. For every term tq in the set of query tokens and their hypernyms, the set of all documents that have a non-zero score for the term is retrieved. The weight of the retrieval is added to the pre-existing score if any, for the document.
The retrieved documents are ordered in descending order of their total scores, and the top 90 percent of retrievals were chosen as candidates for narrative comparison. The final ranking of query results is based on the bag-of-actors similarity score from the previous section on the set of candidates.
Kulkarni et al. [13] addresses the problem of computing exposition similarity computation for given pair of input documents. The approach utilizes a general knowledge base in the form of a term co-occurrence graph (TCG) computed from all articles in Wikipedia, to help in creating a story model for comparison.
In this model, the narrative style or the syuzhet, is modeled as a sequence of topics that are used to narrate the story. This is computed by a random-walk over a term co-occurrence graph (TCG) comprising of nouns, named entities, and verbs, created from the documents; and augmenting it with a general knowledge TCG obtained from Wikipedia.
A stationary distribution obtained from the random walk model, represents an “aboutness” distribution of topics that represent the exposition style. This model of computing aboutness was first proposed by Rachakonda et al. [19].
Exposition similarity between two documents is then measured in two steps:
(1) Measuring the size of “common topic space”
(2) Measuring ranked similarity of aboutness of topical terms
Final Syncretic Similarity score is computed by weighting this similarity score with the joint probability of common topics between the documents.
The proposed method was tested on a hand-crafted test dataset consisting of 22 test cases collected from the Internet. These test cases were on different themes like movies, news articles, and encyclopedic articles. The paper also proposes future work that could further improve the existing methodology.
Narratology is an important area of study, that can help explain several cognitive, social, and cultural phenomena. While the study of narratives has attracted interest from philosophers from a long time, current day advances in computational technology as well as advances in natural language processing, have now opened opportunities for computational modeling of narratives. Breakthroughs in this area is likely to have several implications both in our theoretical understanding of cognition and intelligence, as well as in myriad practical applications.
[1] Haifa Alharthi, Diana Inkpen, and Stan Szpakowicz. 2018. Authorship Identification for Literary Book Recommendations. In Proceedings of the 27th International Conference on Computational Linguistics. 390–400.
[2] Vikas Ganjigunte Ashok, Song Feng, and Yejin Choi. 2013. Success with style: Using writing style to predict the success of novels. In Proceedings of the 2013 conference on empirical methods in natural language processing. 1753–1764.
[3] JG Carbonell, RC Schank, and CK Riesbeck. 1981. Inside computer understanding: Five programs plus miniatures. (1981).
[4] Cristian Danescu-Niculescu-Mizil and Lillian Lee. 2011. Chameleons in imagined conversations: A new approach to understanding co-ordination of linguistic style in dialogs. In Proceedings of the 2nd Workshop on Cognitive Modeling and Computational Linguistics. Association for Computational Linguistics, 76–87.
[5] Ronald de Sousa. 2000. Artificial intelligence and literary creativity: Inside the mind of BRUTUS, a storytelling machine. Computational Linguistics 26, 4 (2000), 642–647.
[6] Konstantin Nicholas Dörr. 2016. Mapping the field of algorithmic journalism. Digital Journalism 4, 6 (2016), 700–722.
[7] David K Elson. 2012. Detecting story analogies from annotations of time, action and agency. In Proceedings of the LREC 2012 Workshop on Computational Models of Narrative, Istanbul, Turkey.
[8] David K Elson, Nicholas Dames, and Kathleen R McKeown. 2010. Extracting social networks from literary fiction. In Proceedings of the 48th annual meeting of the association for computational linguistics. Association for Computational Linguistics, 138–147.
[9] Monika Fludernik. 2009. An introduction to narratology. Routledge.
[10] Jonathan Gottschall. 2012. The storytelling animal: How stories make us human. Houghton Mifflin Harcourt.
[11] Harry Halpin, Johanna D Moore, and Judy Robertson. 2004. Automatic Analysis of Plot for Story Rewriting.. In EMNLP. 127–133.
[12] Hua He, Denilson Barbosa, and Grzegorz Kondrak. 2013. Identification of speakers in novels. In Proceedings of the 51st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Vol. 1. 1312–1320.
[13] Sumant Kulkarni, Srinath Srinivasa, and Tahir Dar. 2018. Syncretic matching: story similarity between documents. In Proceedings of the ACM India Joint International Conference on Data Science and Management of Data. ACM, 146–156.
[14] Birte Lönneker, Jan Christoph Meister, Pablo Gervás, Federico Peinado, and Michael Mateas. 2005. Story generators: Models and approaches for the generation of literary artefacts. In the 17th Joint International Conference of the Association for Computers and the Humanities and the Association for Literary and Linguistic Computing. 126–133.
[15] Stephanie M Lukin, Kevin Bowden, Casey Barackman, and Marilyn A Walker. 2016. PersonaBank: A Corpus of Personal Narratives and Their Story Intention Graphs.. In LREC.
[16] Inderjeet Mani. 2012. Computational modeling of narrative. Synthesis Lectures on Human Language Technologies 5, 3 (2012), 1–142.
[17] Ben Miller, Ayush Shrestha, Jennifer Olive, and Shakthidhar Gopavaram. 2015. Cross-Document Narrative Frame Alignment. In OASIcs-OpenAccess Series in Informatics, Vol. 45. Schloss Dagstuhl-Leibniz-Zentrum fuer Informatik.
[18] François Portet, Ehud Reiter, Albert Gatt, Jim Hunter, Somayajulu Sripada, Yvonne Freer, and Cindy Sykes. 2009. Automatic generation of textual summaries from neonatal intensive care data. Artificial Intelligence 173, 7-8 (2009), 789–816.
[19] Aditya Ramana Rachakonda, Srinath Srinivasa, Sumant Kulkarni, and M.S. Srinivasan. 2014. A generic framework and methodology for extracting semantics from co-occurrences. Data Knowledge Engineering 92 (2014), 39 – 59.
[20] Brian J Reiser, John B Black, and Wendy G Lehnert. 1985. Thematic knowledge structures in the understanding and generation of narratives. Discourse Processes 8, 3 (1985), 357–389.
[21] Nils Reiter, Anette Frank, and Oliver Hellwig. 2014. An NLP-based cross-document approach to narrative structure discovery. Literary and Linguistic Computing 29, 4 (2014), 583–605.
[22] Iulian Vlad Serban, Ryan Lowe, Peter Henderson, Laurent Charlin, and Joelle Pineau. 2015. A survey of available corpora for building data-driven dialogue systems. arXiv preprint arXiv:1512.05742 (2015).
[23] Swapna Somasundaran, Michael Flor, Martin Chodorow, Hillary Molloy, Binod Gyawali, and Laura McCulla. 2018. Towards Evaluating Narrative Quality In Student Writing. Transactions of the Association for Computational Linguistics 6 (2018), 91–106.
[24] Sharath Srivatsa and Srinath Srinivasa. 2018. Narrative Plot Comparison Based on a Bag-of-actors Document Model. In Proceedings of the 29th on Hypertext and Social Media. ACM, 136–144.
[25] Nava Tintarev, Ehud Reiter, Rolf Black, Annalu Waller, and Joe Reddington. 2016. Personal storytelling: Using Natural Language Generation for children with complex communication needs, in the wildâÄÄ. International Journal of Human-Computer Studies 92 (2016), 1–16.
[26] Scott R Turner. 1993. Minstrel: a computer model of creativity and storytelling. (1993).
[27] Rafael Pérez y Pérez. 1999. MEXICA: A computer model of creativity in writing. University of Sussex.
[28] Rafael Pérez y Pérez and Mike Sharples. 2004. Three computer-based models of storytelling: BRUTUS, MINSTREL and MEXICA. Knowledge-based systems 17, 1 (2004), 15–29.
