
Processors have become ubiquitous in all the appliances and machines we use, in both consumer and industrial settings. These processors range from extremely small and low power micro-controllers (used in motor controls, home robots and appliances) to high-performance multi-core processors (used in servers and supercomputers). However, the growth of modern AI/ML environments (like Caffe[Jia et al. 2014], Tensorflow[Abadi et al. 2016]) and the need for features like enhanced security has forced the industry to look beyond general purpose solutions and towards domain-specific-customizations. While a large number of companies today can develop custom ASICs (Application Specific Integrated Chips) and license specific silicon blocks from chip-vendors to develop a customized SoCs (System on Chips), at the heart of every design is the processor and the associated hardware. To serve modern workloads better, these processors also need to be customized, upgraded, re-designed and augmented suitably. This requires that vendors/consumers have access to appropriate processor variants and the flexibility to make modifications and ship them at an affordable cost.
Today, the processor market is dominated by just a few large companies like Intel, ARM and AMD. Each of these companies has an extensive portfolio of processors catering to various market segments. Of these only ARM has a model of licensing processors cores to other companies. Even when processor cores can be licensed, the license is usually very restrictive limiting changes to the ISA and typically has a strict NDA that prohibits publishing data like performance figures.
The struggle against such closed-source IP is not new. The software industry too has overcome the barriers of closed sourced products through the mass adoption of open source. The arrival of the world-wide-web in the 1990s made it possible to share code online, further boosting the growth of open-source software like Linux, GNU and Postgres. Today, the software community is armed with a veritable arsenal of open-source products which have been widely adopted. The hardware community however, has not seen such a revolution yet. An open-source processor eco-system will not only usher in the era of customized processors but also allow industry and academia to collaborate in creation of the next generation of processors. SHAKTI [Gala et al. 2016], an open-source initiative by IIT-Madras (Indian Institute of Technology, Madras) is aimed precisely at building such open-source processor development eco-systems, enabling community with enough resources to build customized, production grade processors, without the attendant hassle of licensing, NDAs, royalties or any other sort of restrictions.
The SHAKTI Processor Program, was started as an academic initiative back in 2014 by the RISE Group at IIT-Madras. Seeking to overcome the limitations of the processor industry mentioned above, the initiative aims at not only creating open-source processors but also building associated components of the eco-system – interconnect fabrics, scalable verification platforms, peripheral IPs and software tools – thereby enabling rapid adoption. Some of the major highlights of the program are:
(1) Source code of all the HW components of the SHAKTI eco-system is open under the 3 part BSD license, the SW is released under GPL. This means a user could freely use, modify and circulate the source code without having to sign any NDAs, licenses or even notify the authors as long as the license terms are met. The SHAKTI program itself will not assert any patents and thereby removes the burden of patent encumbrance.
(2) The processors of the SHAKTI program are based on the open RISC-V [RISC-V 2015] ISA (In- struction Set Architecture). RISC-V has been designed for modularity and extensibility, enabling easy-customization and is supported by a comprehensive SW and tools eco-system. Since the ISA does not dictate micro-architectural features, the software and hardware can be maintained by two complete different entities and yet be compatible.
(3) The front-end (RTL – Register Transfer Level) design of the SHAKTI processors are developed in Bluespec, the open-source High Level Synthesis (HLS) language: Bluespec System Verilog (BSV) [Nikhil 2004]. BSV allows the user to develop using a paradigm of parameterized modules with well defined interfaces. There is also an open-source parser available, enabling anyone interested to build their own BSV compiler.
(4) The academic world now has access to a comprehensive family of real world implementations of processors. Typically academic research was restricted to the world of “simulators” and ”emulation models”. Now research results can be proven on actual processors using FPGAs or low-cost academic ASIC fabrication.
(5) An open-source eco-system such as SHAKTI promotes modular development environment where users can plug-in different open-source or proprietary IPs and innovate on new products and designs. Being completely open-source, it is exteremely difficult for external entities to add back-doors and trojans. This is of particular interest to the strategic sectors in countries like India, which today depend on black-box solutions provided by external entities.
In addition to the above advantages, a combination of an open-source processor eco-systems like SHAKTI and a semiconductor fab offering prototype facilities on its latest technology node allows small projects to produce custom processors.
Considering the large universe of applications that processors can cater to today, SHAKTI has envisioned a family of processors as part of its road-map. The 6 major families of SHAKTI processors are shown in Figure-1. The taxonomy of these processors is described in Table-I.
Apart from processors, SHAKTI also offers a large number of components which are necessary to build a working SoC:
(1) AAPG: (Automated Assembly Program Generator) This a python based tool capable of generating directed random tests. As compared to equivalent RISC-V offerings, AAPG provides a variety of useful configuration options to generate specific template tests. More details to follow in later sections.
(2) SLSV: (SHAKTI Lock Step Verification) While AAPG provides the test inputs, we need a frame-work which can check the state of the processor against a golden model. SLSV enables the user to plug-in any two models of a RISC-V implementation (RTL, Simulators, Emulators or formal model) and carry out comparison of states for a given input stimulus. More details of SLSV are presented in Section-5.2.
(3) Rita: (RISC-V Trace Analyzer) RiTA provides statistics of a post execution trace of a program.
Statistics include: instruction histogram, register histogram and branch statistics.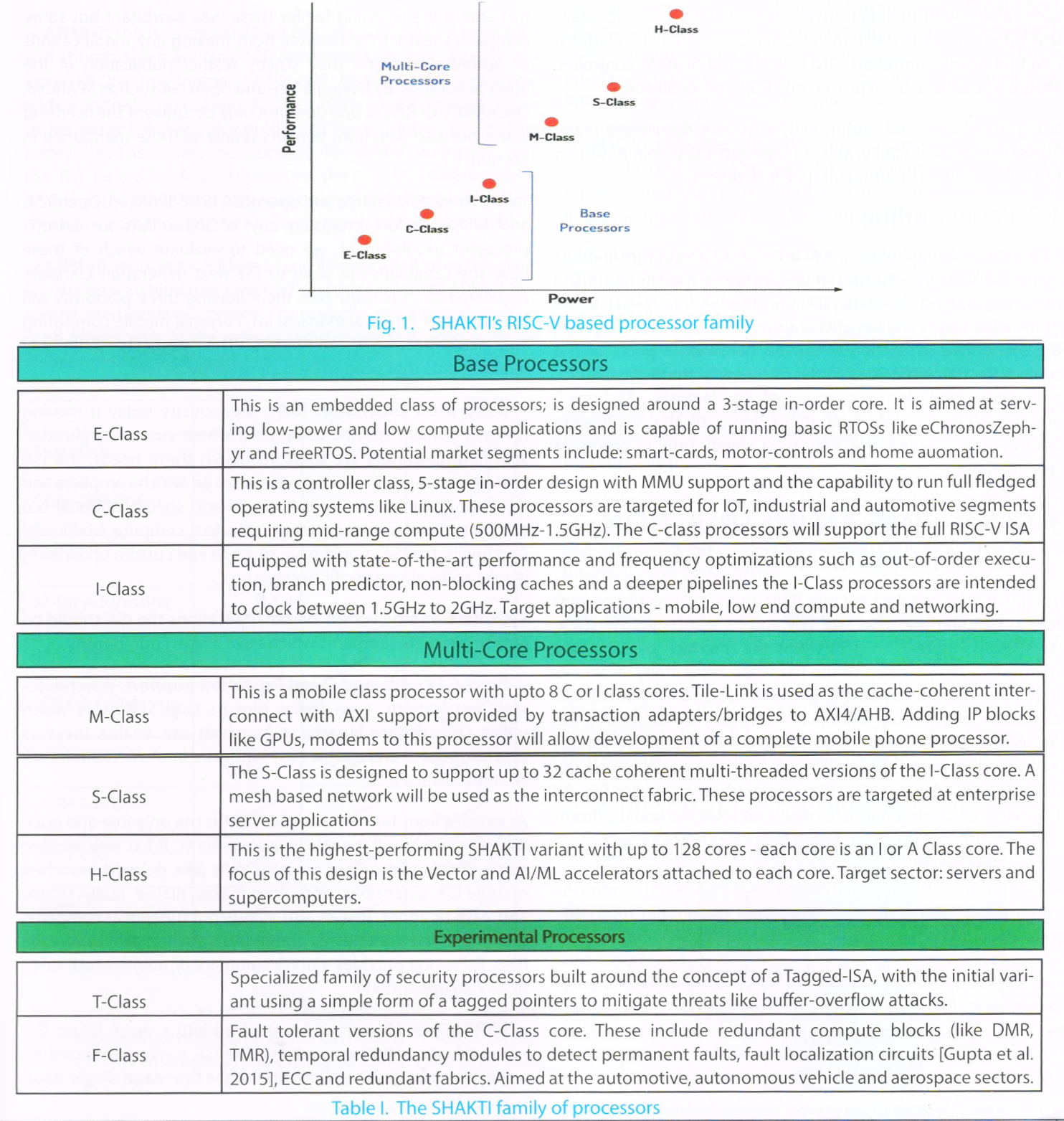
— Interconnect Fabrics: SHAKTI offers a number of implementations of standard interconnect fabrics. It supports AXI-4, AXI-4 Lite and TileLink U/H/C interconnect protocols. Each of these are available as a crossbar switch or a mesh network. Customization of each of these protocols/fabrics is quite easy and compatibility with the standard is maintained, thereby enabling instant integration with third party IPs. SHAKTI also has prototypes of the RapidIO chip-to-chip interconnect fabric and is working on releasing an open-source implementation of the GenZ interconnect.
— Peripheral IPs: The project has released the entire source code, along with minimal drivers, for a variety of peripherals: UART (Rx Tx model), UART-16550, QSPI, I2C, DMA, PLIC (Platform Level Interrupt Controller), ONFI, NvMe and SDRAM controller. Most of these have been proven on FPGA and/or Silicon.
Using the above tools and IP, with a student dominated team, SHAKTI was successfully able to tape-out a test chip based on the C-Class processor using Intel’s 22FFL process.
This paper will highlight some of the choices and design features of the SHAKTI processor program. Section-2 will showcase the reasoning behind choosing RISC-V as the ISA for SHAKTI. Some of the advantages and benefits of using BSV as the HLS language are mentioned in Section-3. On the hard- ware aspects of the project, Section-4 provides a brief overview of the c-class micro-architecture and discusses some of its features. Sections-5 and 6 provide a walk-through of some of the verification issues and meta-platforms that assist significantly in processor development.
The Instruction Set Architecture (ISA), plays the most important role in defining the processor HW and its associated SW stack. As seen Figure-2, the ISA forms the interface between the hardware and software. For the hardware community, it defines important metrics like power, performance and area. A bad ISA can easily lead to huge area overheads, thereby increasing the net power consumption of the chip. For example, the various addressing modes supported by the ISA can easily define the number of read and write ports required on a registerfile. An instruction requiring multiple reads and multiple updates from/to the registerfile will incur a huge overhead.
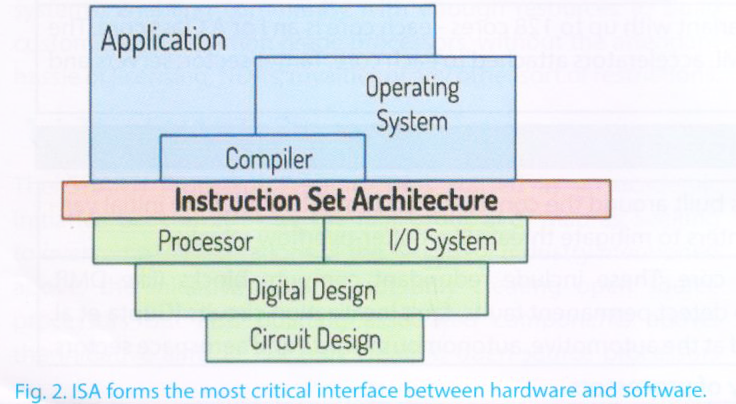
For the software community, the ISA defines the basis for a variety of infrastructure like compilers, operating systems, applications, common libraries, etc. It is this which dictates the flexibility and ease of porting an application or OS onto a platform. A complex and fragmented ISA increases the burden of the software programmer to maintain compatibility across multiple platforms.
Even though it is quite evident that ISA forms the spine of any processor ecosystem (HW and SW both), the industry today poses several viable ISAs, all of which are proprietary. This greatly limits the ability for open processor eco-systems to evolve. Not only is the licensing fee for these ISAs exorbitant but some companies restrict the licensee from making any modifications or optimizations, and they strictly restrict publication of the internal findings. By having a free and open ISA such as SPARCv8, OpenRISCV or RISC-V one does not only circumvent the licensing issues but also gains from benefits similar to those mentioned in Section-1.1.
Today there do exist free and open RISC ISAs: SPARC v8, OpenRISC and RISC-V. Before choosing any of these ISAs for SHAKTI processor development, we need to evaluate which of these have the capabilities to scale to the next generation compute requirements. It is likely that the following three platforms will dominate the future workloads: IoT, Personal mobile computing and Warehouse-scale computers. This suggests three key requirements that need to be supported by an ISA:
—Base Plus Extension ISA: The industry today is moving towards domain specific computing where custom application specific accelerators are used. To match these needs, the ISA should have a small core instruction set on which compilers and OSes can depend on. The ISA should also specify optional but common ISA extensions to serve standard compute workloads. And finally, the ISA should have space to add custom opcodes to invoke application specific accelerators.
—Code Density: For IoT based applications the ISA should be able to generate programs which have a high code density.
—Single, Double and Quad Precision support: Warehouse-scale applications, even today, process large data sets which utilize QP software libraries. ISAs which can enable these as special opcodes and enable easy hardware implementations will be more attractive.
As evident from Table-II, the RISC-V ISA is the only free and open ISA which meets all the above requirements. It has also avoided some of the mistakes of previous ISAs (like delayed branches, module ISA extensions, etc). This makes RISC-V really simple and easy to adopt. RISC-V also stands out superior as compared to some of the commercial competitors such as MIPS and ARM ISAs. Following provides a quick summary of points which gives RISC-V an upper-hand:
—MIPS: Over 30 years, it has evolved into a much larger ISA, now with about 400 instructions.The ISA is overoptimized for a specific micro-architectural pattern, the five-stage,single-issue, in-order pipeline. RISC-V on the other hand does not mandate any micro-architectural features, thereby enabling varied micro-archiectures to exist ranging from simple in-order cores to out-of-order multi- cores.
—Oracle’s SPARC: To accelerate function calls, SPARC employs a large, windowed register file the operating system must be routinely invoked to handle the window overflows and underflows. The register windows come at a significant area and power cost for all implementations. It was designed to be implemented in a single-issue, in-order, five-stage pipeline, and the ISA reflects this assumption.
—ARMv7: This is a popular 32-bit RISC-inspired ISA,Between ARM and Thumb, there are over 600 instructions in the integer ISA alone. NEON, the integer SIMD and floating-point extension, adds hundreds more. Even if it had been legally feasible for us to implement ARMv7, it would have been quite challenging technically.,There was no support for 64-bit addresses, and the ISA lacked hardware support for the IEEE 754-2008 standard. RISC-V on the other hand comprises merely of 40 BASE instructions which any compiler, os and hardware needs to be support.
—ARMv8: With 64-bit addresses and an expanded integer register set. The new architecture removed several features of ARMv7 that complicated implementations. For example, the program counter is no longer part of the integer register set; instructions are no longer predicated; the load-multiple and
store-multiple instructions were removed; and the instruction encoding was regularized. Overall, the ISA is complex and unwieldy. There are 1070 instructions comprising 53 formats and and eight data addressing modes, all of which takes 5,778 pages to document. Finally, like its predecessor, ARMv8 is a closed standard. It cannot be sub-settled, making implementations far too bulky to serve as embedded processors or as control units for custom accelerators.
—Intel’s 8086 architecture: Outside of the domain of embedded systems, virtually all popular software has been ported to, or was developed for, the x86.
In addition to the features listed in Table-II, the RISC-V ISA also clearly separates the user-mode ISA from the privileged mode ISA, allowing full virtualization and enabling experimentation in the privileged ISA while maintaining user application binary interface (ABI) compatibility. Some more features which make RISC-V an atttractive ISA for the future are:
(1) RISC-V separate the ISA into a small base ISA and optional extensions. The base ISA is lean enough to be suitable for educational purposes and for many embedded processors, including the control units of custom accelerators.
(2) Support both 32-bit and 64-bit address spaces, as 32-bit will continue to be popular in small systems for centuries while the latter is desirable even for modest personal computers.
(3) Facilitate custom ISA extensions, including tightly coupled functional units and loosely coupled accelerators
(4) Support variable-length instruction set extensions, both for improved code density and for expanding the space of possible custom ISA extensions
(5) Orthogonalize the user ISA and privileged architecture, allowing full virtualizability and enabling experimentation in the privileged ISA while maintaining user application binary interface (ABI) compatibility.
The RISC-V ISA is now maintained officially by the RISC-V foundation [RISC-V 2015] which is supported by more than 100+ members. The arguments and facts presented in this section make it even more clear that not only should all computing devices adopt a free and open ISA but also adopt RISC-V for its potential to scale for future workloads. The SHAKTI program has thus adopted RISC-V as its standard base ISA.
Another critical aspect of developing processors is to choose the right description language to design them. As mentioned in the earlier sections, one of the primary reasons of building open-source processor eco-systems is the reusability of the code-base and the IP. This requires the micro-architecture description to be easily understandable, quick to modify and fast to prototype. Additionally, these description languages also need to be open-source and cannot be proprietary for similar reasons mentioned in section-2 (as shown by the need for reverse-engineering of FPGAs: it’s no good releasing the HDL source for a design if the toolchain for compiling it to an FPGA target costs more).
While the industry has standardized on using Verilog and VHDL for all production grade chips over the past three decades, these languages suffer from several limitations making them a bad choice to develop next-gen processors. Both of these languages were intended to enable simulation of digital circuits. It was later when people started adopting them for logic synthesis as well. However, the fact that each of these languages hold constructs which cannot be synthesized makes them difficult to use for designing complex processors. Another major barrier while using these languages is the low-level of abstraction that is offered. Defining complex designs using Verilog will require mapping the abstracted spec definition to be correctly mapped to low-level gate structures. This leads to large number of human-errors in the design. Modern software engineers familiar with Object Oriented Programming Languages such as Python, C++, Rust, etc. look at this situation with a significant degree of bewilderment and disbelief, and older software engineers will easily recognize both Verilog and VHDL as containing stagnated constructs and design methodologies from software languages developed as far back as the 1980s. To overcome some of the major limitations of Verilog and VHDL, the industry has seen a growth in High-Level-Synthesis languages: Bluespec System Verilog (BSV) [Nikhil 2004], Chisel [Bachrach et al. 2012], Clash [Baaij et al. 2010], SystemC [sys 2012], SystemVerilog [sys 2018] etc. Languages like BSV and Chisel are open-source and anyone is at liberty to build their own compilers and libraries to support the language constructs. The SHAKTI ecosystem uses Bluespec System Verilog for its development owing to the following reasons:
—Architecturally Transparent: BSV is architecturally transparent and the designer has complete control over defining explicitly the architecture of the design. The powerful types and static elaboration enable the user to express architecture elegantly and succinctly. Since static elaboration is deterministic, the HSL does not create surprises for the user.
—Superior Behavioral Semantics: BSV supports atomic rules and parameterized interface definitions. The atomic nature of rules allow for a higher-abstracted definition of the concurrency nature of the architecture. The interfaces in BSV allow you bundle different combinations of ports (like input, output, etc) as sub-interfaces and methods, thus avoiding the rats-nest-like code found in Verilog and VHDL.
—Strong Parameterization: BSV has a strong parameterization (templates, similar to c++) feature which improves code size, code-structure, code-reuse and correctness. This feature allows a user to define parameterized modules, interfaces and functions to generate interfaces and modules, nested rules, etc. This provides the user with higher expressive power.
—Guaranteed Synthesis: The constructs and structure defined by BSV are completely synthesizable. This enables the user to quickly prototype their designs on FPGAs from day one without facing any synthesis issues (like loops, latches etc.). BSV also enables generating synthesizable test-benches which can ported to FPGAs as well.
Today, Bluespec Inc. provides a BSV compiler which can generate both synthesizable Verilog and a cycle-accurate C model of the BSV design. The C model is known to be nearly 8-10x faster in simulation when compared to state-of-the-art verilog simulators in the market. This drastically speeds up verification process of designs, thereby leading to quick turn around time and reduced time to market. All of the above mentioned points makes BSV a sensible risk-reducing choice on which RISC-V based processors can be designed.
In this section, we will describe the micro-architecture of the SHAKTI C-class processor that is open- sourced. This processor has also been taped-out on Intel’s 22nm FFL technology node [Intel Corporation]. Figure-3 shows a high-level block diagram of the C-class processor.
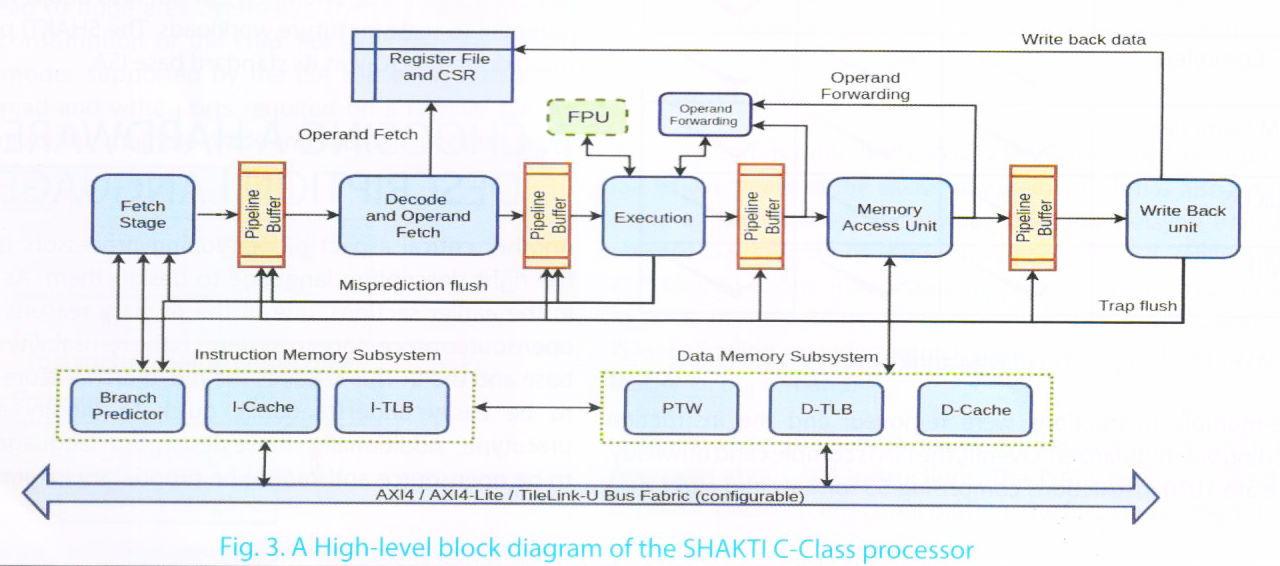
The following subsections will define the function of each stage in detail. Please note, that this a walk-through of one particular implementation of the SHAKTI C-class processor. Due to continuous development of the core, one may find some of the details to be obsolete when referring to the current online publicly-available source code.
This is the very first stage of the processor pipeline. The fetch stage is responsible for generating a new program counter (PC) and sending it to the instruction memory subsystem. The fetch unit also includes a small Return-Address-Stack (RAS) to help reduce delay penalties on function returns.
4.1.1 Branch Predictor and RAS. Within the memory subsystem, the program counter is sent to three modules simultaneously: the branch predictor, the instruction cache and the instruction TLB (Translation Look-aside Buffer). The branch predictor performs a check if the current program counter points to an instruction which is a conditional branch. If so, it checks the probability with which the branch will be taken and also provides the target address of the jump. If the probability of branching is low then the predictor simply returns the next consequent PC value.
The data structure within the branch predictor which maintains the probability of the indirection is known as the prediction table, and the data structure which holds the indirection address is known as the branch target buffer (BTB). In the RISC-V ISA, a conditional branch range is ±4KiB. This means that the BTB needs to simply hold a 12-bit offset value which can get added to the current PC to generate the branch address, thereby reducing the storage requirements of the branch predictor.
The RISC-V ISA also includes unconditional jump instructions (JAL and JALR) which are typically used for function calls and returns. Since a function call and its return follows a structured pattern, an RAS data structure is used to keep track rather than training the branch predictor for these instructions. The ISA also provides hints within the instruction encoding which allows for a quick detection of call or return operation in the fetch stage itself. A call operation will push the return address on top of the RAS stack and a return operation will pop the return address from the address and send it to the instruction memory subsystem for fetching the relevant instruction. Maintaining the RAS reduces the number of collisions within the branch predictor which otherwise would have happened if trained with call and return instructions.
4.1.2 Instruction Cache and TLB. Since the SHAKTI C-Class supports virtualization, the instruction cache is a VIPT (Virtually Indexed and Physically Tagged) structure. The BSV code of the cache has been designed to generate a parameterized cache which can range from 16-64KiB. The cache is blocking in nature, i.e. unless a previous request is served (whether hit or miss) the next request is stalled. The C-class processor also holds a 16-entry fully-associative TLB which is accessed simultaneously as the cache is accessed. The TLB stores the physical page number of the page present in memory. The TLB look-up takes a single cycle. In the next cycle, the TLB provided physical page number is compared with the tag from the cache. If they match, a hit is indicated and the respective instruction is fetched from the data array. In case they do not match, the cache initiates a new line- request from the next memory level. The line-request from the lower hierarchy memory should ensure that the critical word is retrieved first so that the fetch request can be served as soon as possible.
This stage receives the instruction from the fetch unit, decodes it into crucial fields like: operand addresses, destination address, operation type, immediate field, etc. Once the operand addresses are available the registerfile (which holds 32 64-bit integer registers and 32 64-bit floating point registers) is accessed to fetch the respective operands. Since all the base ISA integer instructions require only a maximum of 2 operands and update only a single operand, the integer registerfile requires 2 read-ports and 1 write port. The floating point instructions like FMADD, FMSUB, etc. require 3 operands and thus the floating point registerfile require 3 read-ports and 1 write port. Other fields of the instruction are re-coded to a format which is more convenient for the next stage to execute.
Another important activity of this stage is to capture all interrupts and exceptions. The CSRs (Control Status Registers) are looked up in this stage to indicate if an interrupt has occurred. If so, then the trap field of the next pipeline buffer is set with the relevant information which will enable the processor to handle the interrupt. Other exceptions like illegal instructions, illegal CSR accesses are also captured here before the instruction proceeds.
This stage holds the ALU which performs the necessary arithmetic operation required by the instructions. To achieve this it holds the integer arithmetic unit, the variable-cycle multiplier with early-out mechanism, a non-restoring sequential divider and a floating point unit which supports IEEE-754 single and double precision arithmetic. This is also the stage where the prediction of the branch predictor is validated. An instruction whose operands were not available in the decode stage are stalled in this stage until the operand forwarding logic provides the necessary operands. The operand forwarding logic receives values from the next pipeline buffer for arithmetic operations and from the memory stage for values from load instructions.
Unless designed carefully and meticulously, the ALU has the potential of being not only the most delay-sensitive path but also be the most area burdened unit as well. C-Class, being an in-order core, employs sequential multiplier and divider circuits which share a lot of hardware. The multiplier has an early-out mechanism, which means the results can be available anywhere between 1 to 8 cycles as soon as one of the shifted operands is made 0. The divider however implements a non-restoring algorithm which requires up to 64 cycles for an RV64 ISA. The floating point unit is also designed to be low overhead in terms of area and thus implements a sequential algorithm for fused-multiply-add operations which re-uses significant amount of hardware compared to a pipelined version. For memory operations, the address generated by the ALU is directly latched into the data memory subsystem to initiate the load/store process. If, however, there is a trap from the write-back stage, then the pipeline is flushed and the load/store address is not latched, thereby preventing corruption of memory.
The execute stage also checks if either the load/store addresses or the conditional branch addresses are misaligned, and raises a suitable exception and progresses the instruction forward.
All non-load/store/atomic operations will simply bypass this stage and proceed to the write-back stage. In case of a load/store instruction, this stage captures the result of the memory access. For a load operation, the data is forwarded to the execution unit for instructions that depend on the loaded value. All exceptions related to load/stores such as access-fault, page-fault, etc. are captured here. The data-memory subsystem works in the same manner as the instruction memory subsystem as described earlier. A page table walk is initiated if there is a TLB miss.
This is the stage where the instruction retires. This stage first checks if the instruction has been tagged with any traps (interrupt or exceptions) by the previous stages. If a trap is to be taken, then the entire pipeline is flushed and the first instruction of the trap handler is fetched. If no traps are present, then the instruction simply updates the register with the new value. All CSR related operations also take effect here.
Verification of a processor consumes nearly 60-65% of the average processor development cycle. It is almost impossible to completely verify a processor given the large exponential solution space. It order to verify a processor, one does not only need to check the compliance of the processor with the ISA spec, but also verify the various ISA independent micro-architectural states and circuits like: hazard detection, operand forwarding, branch predictors, cache optimizations. While one could easily develop a bottom-up approach to verify create a verification suite of test-benches for each module, but even that would require analyzing and identifying all possible inputs and scenarios when the module is plugged in to larger system. While, the bottom-up approach is a needed task, it should be limited to verifying the base functionality only to keep the turn-around time small.
A processor verification team, typically writes a series of software routines in assembly or C, which excite and test specific aspects of the processor. Considering the large state-space of the processor, manually writing these tests to cover even 80% of the states would take significant amount of time, thereby increasing the time to market. An approach to reduce this effort is to use random program generators for the processor. While these generators do not guarantee to provide full coverage, but a lot of base-case scenarios can easily be covered and the user is burdened with writing only a few specific directed test cases for the processor system.
In order to verify the C-class core, we have used multiple random program generators:
(1) RISC-V Torture [RISC-V Torture 2012]:This is a random assembly program generator from UC Berkely. A user can specify the total size of the program and also define the distribution count of various instruction extensions within the program.
(2) CSMITH [Yang et al. 2011]: This is random C-program generator from the University of Utah.
CSMITH can generate program which are illegal and cannot be ported to RISC-V, and thus care needs to be taken to ensure valid programs are only used to test the processor.
(3) AAPG (Automated Assembly Program Generator):This is a Python based SHAKTI developed tool, which can generate directed random assembly programs. The following section provides more details about the tool and its usage in verifying the C-class processor.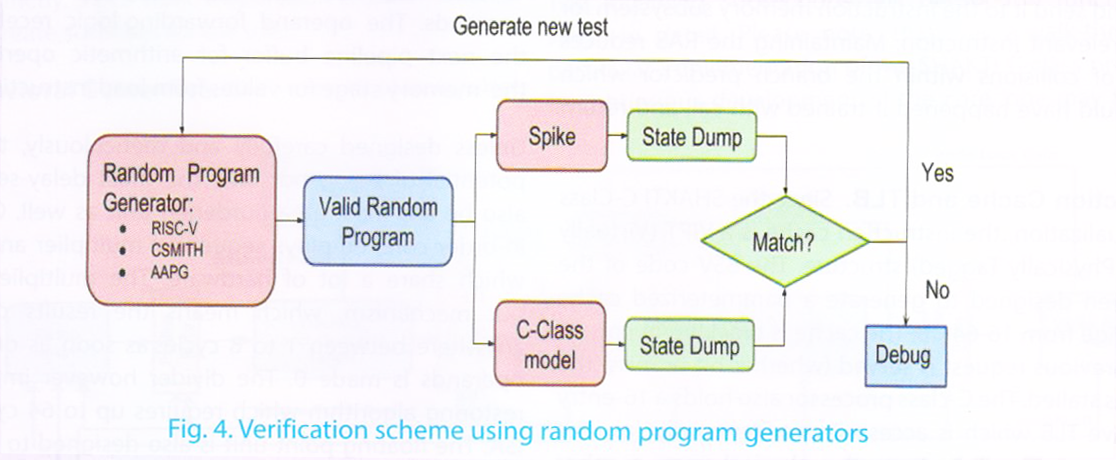
Each of the above generators are used to generate programs which are then run on the processor model platform. The correctness of execution is checked by comparing the architectural state of the processor after every instruction with that of a golden instruction set simulator. Figure-4 shows how one can perform verification using these tools.
AAPG is a more robust tool as compared to its contemporaries. The tool is entirely developed in python and provides the user a much more finer control over generation as compared with other tools. Some of the features include:
(1) Nested Loops: The user can specify the depth of nested loops, size of each loop and the number of such nested instances. The user can also specify the instruction distribution within a loop. These parameters can be used to validate the branch predictors.
(2) Number of Forward Jumps: The user can specify an approximate number of forward and backward jumps.
(3) Recursive calls: AAPG provides a recursive template which can be configured in the number of calls and the type of instructions within each call.
(4) Cache Thrashing sequences: AAPG also provides a i-cache and d-cache thrashing template where the user only needs to provide certain parameters of the cache, such as number of ways, number of sets, etc.
(5) Data Access distribution: The user can specify which section of the data segment should be accessed how many number of times.
(6) Exception Generation: AAPG allows the user to specify the kinds of exceptions that need to be generated and also provide a place-holder to custom trap handler routines.
While the previous section describes an automated way of generating tests, there still exists the huge time penalties of running these simulations. While the Bluesim environment, which executes the cycle- accurate C model of the design, does accelerate simulation by nearly 8-10x than standard verilog RTL simulators, the simulation times are still high for large applications. Additionally, in order to create the state-dump a file-io is required which can also consume significant time during simulations. Another issue with the state-matching scheme mentioned in Figure-4 is that it is not real-time. Thus, a bug which occurs much early in the simulation can only be detected when the simulation completes or is terminated. This increases the turn-around time for bug detection and fixes.
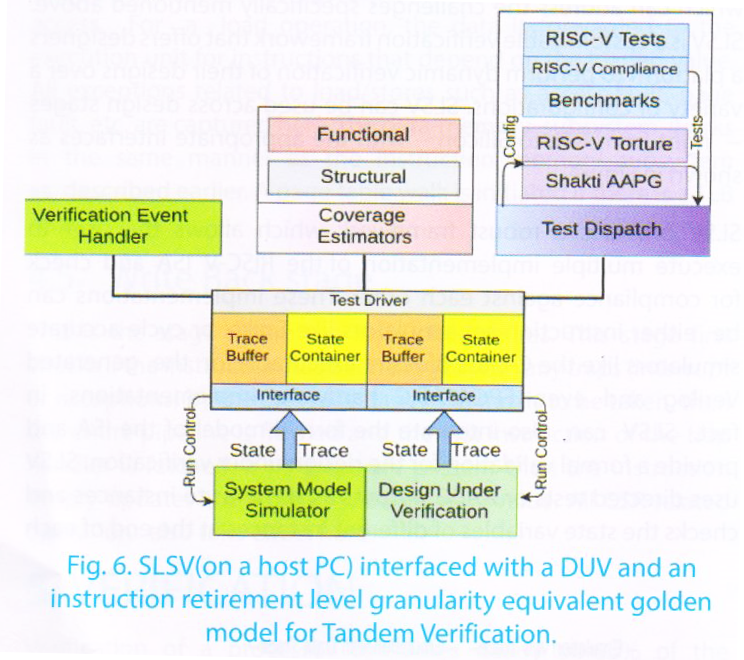
SHAKTI offers, the SLSV (SHAKTI Lock Step Verification) framework which can address the challenges specifically mentioned above. SLSV is a customizable verification framework that offers designers a platform to perform dynamic verification of their designs over a variety of configurations. SLSV can be used across design stages – right from RTL to Silicon – with the appropriate interfaces as shown in Figure-5.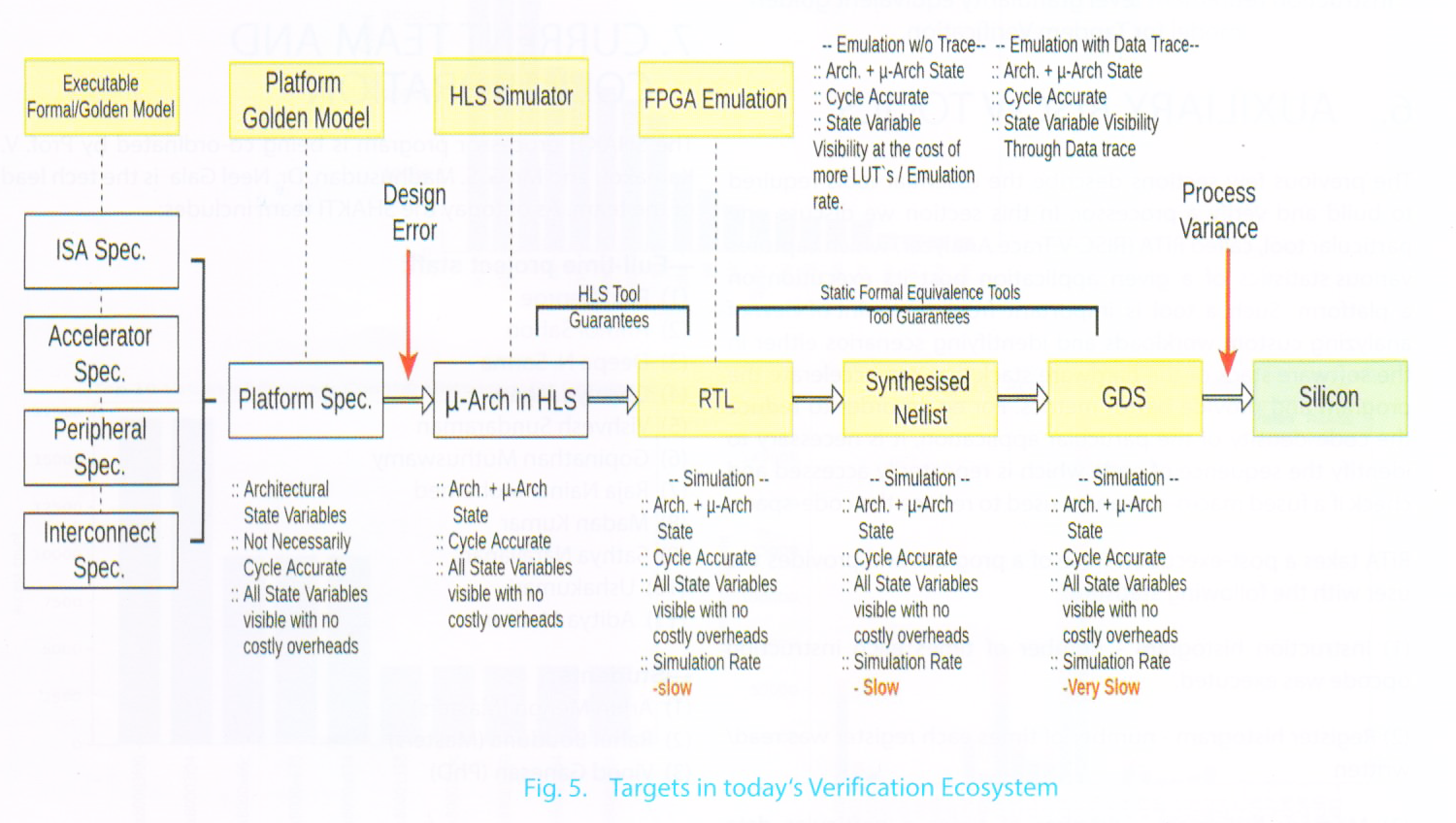
SLSV provides a robust framework which allows the user to execute multiple implementation of the RISC-V ISA and check for compliance against each other. These implementations can be either instruction set simulators like Spike, or cycle accurate simulators like the c-class Bluesim executable, or the generated verilog and even FPGA/ASIC hardware implementations. In fact, SLSV can also integrate the formal model of the ISA and provide a formal validation the design under verification. SLSV uses directed tests or AAPG outputs as stimulus to instances and checks the state variables of different instances at the end of each instruction.
SLSV is independent of the interface used by the implementation to communicate the state-variables. It can use simple file-io to interact with simulation models or use JTAG sequences to interact with FPGA platforms and even use customized trace protocols to collect more information. Other than merely comparing states across implementations, SLSV also offers the potential of providing a test- coverage metric, event handlers, event distributors, etc. as shown in figure-5.2. SLSV is thus aimed at not improving verification speeds, but also providing the user a constructive feedback on the state variables being accessed by the current stimulus.
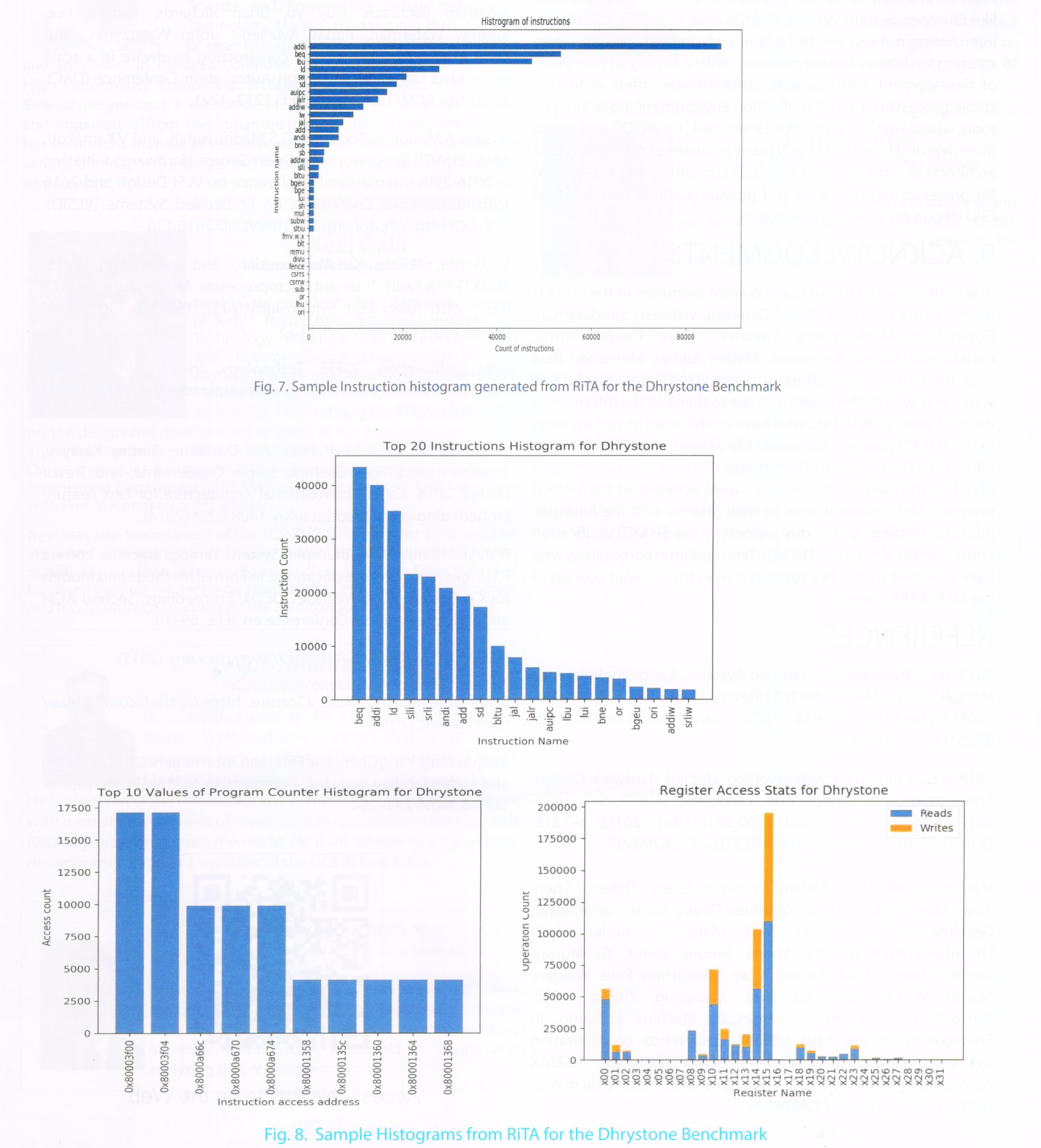
The previous few sections describe the essential tools required to build and verify a processor. In this section we discuss one particular tool, called RiTA (RISC-V Trace Analyzer) which captures various statistics of a given application post its execution on a platform. Such a tool is important from the point of view of analyzing custom workloads and identifying scenarios either in the software stack or the hardware stack than can accelerate the program and provide better metrics. For eg, in order to reduce the code-density of the particular application, it is necessary to identify the sequence of code which is repeatedly accessed and check if a fused macro-op can be used to reduce the code-space.
RiTA takes a post-execution trace of a program and provides the user with the following statistics:
(1) Instruction histogram – number of times each instruction opcode was executed.
(2) Register histogram – number of times each register was read/written.
(3) Memory histogram – number of times a particular data segment address was read/written.
(4) Branch statistics – number branches, taken branches, forward branches, backward branches, etc.
(5) Loop statistics – number of loops, size of a loop, iterations within a loop, etc.
(6) Sequence statistics – Identify whether a user-defined sequence of dependent instructions exists in the trace or not and also the number of times it has occurred.
RiTA is designed as a tiered application. This structure helps to keep different parts of the system de-coupled and thus helps in extensibility and plugging it into other frameworks. The first layer of RiTA is the trace source parser. The parser plays the role of reading in the input data and extracting the necessary details from it. In the current architecture the parser accepts a log file as an input. By using regular expression matching, we are able to extract the machine hex which corresponds to each instruction. This machine hex is then passed on to the next layer which is the instruction parser.
The machine hex opcode can be used to extract the necessary bit-fields like opcode, target regis- ter, source registers and then use this information in further statistics. The final layer is the post- processing module. The post-processing modules are all independently written so users can share the modules they write. Creating a new post-processing module is as easy as copying an existing one and modifying the source code to match your implementation.
The SHAKTI processor program is being co-ordinated by Prof. V. Kamakoti and Mr. G. S. Madhusudan.
Dr. Neel Gala is the tech lead of the team. As of today the SHAKTI team includes:
—Full-time project staff:
(1) Paul George
(2) Anmol Sahoo
(3) Deepa N. Sarma
(4) Lavanya Jagan
(5) Vishvesh Sundaraman
(6) Gopinathan Muthuswamy
(7) Raja Nainar Mohamed
(8) Madan Kumar
(9) Sathya Narayanan
(10) Ushakumari
(11) Aditya Mathur
—Students:
(1) Arjun Menon (Masters)
(2) Rahul Bodduna (Masters)
(3) Vinod Ganesan (PhD)
—Remote Collaborators:
(1) Luke Leighton – An advocate for Libre licensed hardware and software.
Each of the members work in different specializations of SHAKTI: core design, peripheral development, operating systems, verification, specialized accelerators, etc. The SHAKTI team is always open for any sort of collaboration and interested users/parties are requested to reach out to either Prof. V. Kamakoti, or G. S. Madhusudan or Neel Gala for any queries.
With a powerful ISA like RISC-V being open-source, the hardware community (like the software com- munity) will start seeing its share of plethora of industrial grade open-source processors and tools in the near future. Enabled by an open HLS language like Bluespec System Verilog, SHAKTI aims to be forerunner in providing not just one, but a family of open-source processors catering to distinct market domains. With history of four years of development and research, SHAKTI today offers upto two stable processors, robust verification environment, trace analysis tools, associated OS ports like Linux, sel4, FreeRTOS and much more. Moving forward, SHAKTI plans to create a critical mass CPU architects in India, create a vigorous concept-to-fab eco-system for processor development and provide a sturdy and practical CPU design engineering curriculum.
The authors would like to thank current members of the SHAKTI team – Rahul Bodduna, Vinod Ganesan, Vishvesh Sundaraman, Gopinathan Muthuswamy, Lavanya Jagan, Deepa Sarma, Ushakumari, Sathya Narayanan, Madan Kumar, Mohamed Raja – for their continuous effort to make SHAKTI a successful and viable eco-system. We would also like to thank all the interns over the past years at RISE Lab, who have contributed in various ways to the SHAKTI program. We would like extend our gratitude to the Ministry of Electronics and Information Technology, Government of India, who have sponsored significant activities of the SHAKTI program. Our sincere thanks to Niraj Sharma and the Bluespec Inc. for providing continuous support to the SHAKTI verification effort. Credits also extend to HCL Tech and Intel corporation who have provided a pillar like support during the tapeout process of the RISECREEK chip.
REFERENCES
2012. IEEE Standard for Standard SystemC Language Reference Manual. IEE Std 1666-2011 (Revision of IEEE Std 1666-2005) (Jan 2012), 1–638. DOI:http://dx.doi.org/10.1109/IEEESTD.2012.6134619
2018. IEEE Standard for SystemVerilog–Unified Hardware Design, Specification, and Verification Language. IEEE Std 1800-2017 (Revision of IEEE Std 1800-2012) (Feb 2018), 1–1315. DOI: http://dx.doi.org/10.1109/IEEESTD.2018.8299595
Martin Abadi, Paul Barham, Jianmin Chen, Zhifeng Chen, Andy Davis, Jeffrey Dean, Matthieu Devin, Sanjay Ghemawat, Geoffrey Irving, Michael Isard, Manjunath Kudlur, Josh Levenberg, Rajat Monga, Sherry Moore, Derek G. Murray, Benoit Steiner, Paul Tucker, Vijay Vasudevan, Pete Warden, Martin Wicke, Yuan Yu, and Xiaoqiang Zheng. 2016. TensorFlow: A System for Large-scale Machine Learning. In Proceedings of the 12th USENIX Conference on Operating Systems Design and Implementation (OSDI’16). USENIX Association, Berkeley, CA, USA, 265–283. http://dl.acm.org/citation.cfm?id=3026877.3026899
Christiaan Baaij, Matthijs Kooijman, Jan Kuper, Arjan Boeijink, and Marco Gerards. 2010. CλaSH: Structural Descriptions of Synchronous Hardware using Haskell. In Digital System Design: Architectures, Methods and Tools (DSD), 2010 13th Euromicro Conference on. IEEE, 714–721.
Jonathan Bachrach, Huy Vo, Brian Richards, Yunsup Lee, Andrew Waterman, Rimas AvizËienis, John Wawrzynek, and Krste Asanovic´. 2012. Chisel: constructing hardware in a scala embedded language. In Design Automation Conference (DAC), 2012 49th ACM/EDAC/IEEE. IEEE, 1212–1221.
N. Gala, A. Menon, R. Bodduna, G. S. Madhusudan, and V. Kamakoti. 2016.SHAKTI Processors: An Open-Source Hardware Initiative. In 2016 29th International Conference on VLSI Design and 2016 15th International Conference on Embedded Systems (VLSID). 7–8. DOI: http://dx.doi.org/10.1109/VLSID.2016.130
S. Gupta, N. Gala, G .S. Madhusudan, and V. Kamakoti. 2015.SHAKTI-F: A Fault Tolerant Microprocessor Architecture. In 2015 IEEE 24th Asian Test Symposium (ATS). 163–168. DOI: http://dx.doi.org/10.1109/ATS.2015.35
Intel Corporation. 22FFL Technology. In
https://newsroom.intel.com/newsroom/wp- content/uploads/sites/11/2017/03/Mark-Bohr-22FFL-2017.pdf
Yangqing Jia, Evan Shelhamer, Jeff Donahue, Sergey Karayev, Jonathan Long, Ross Girshick, Sergio Guadarrama, and Trevor Darrell. 2014. Caffe: Convolutional Architecture for Fast Feature Embedding. arXiv preprint arXiv:1408.5093 (2014).
Rishiyur Nikhil. 2004. Bluespec System Verilog: efficient, correct RTL from high level specifications. In Formal Methods and Models for Co-Design, 2004. MEMOCODE’04. Proceedings. Second ACM and IEEE International Conference on. IEEE, 69–70.
RISC-V. 2015. RISC-V ISA. https://www.riscv.org (2015).
RISC-V Torture. 2012. RISC-V Torture. https://github.com/ucb-bar/riscv-torture (2012).
Xuejun Yang, Yang Chen, Eric Eide, and John Regehr. 2011. Finding and understanding bugs in C
compilers. In ACM SIGPLAN Notices, Vol. 46. ACM, 283–294.
